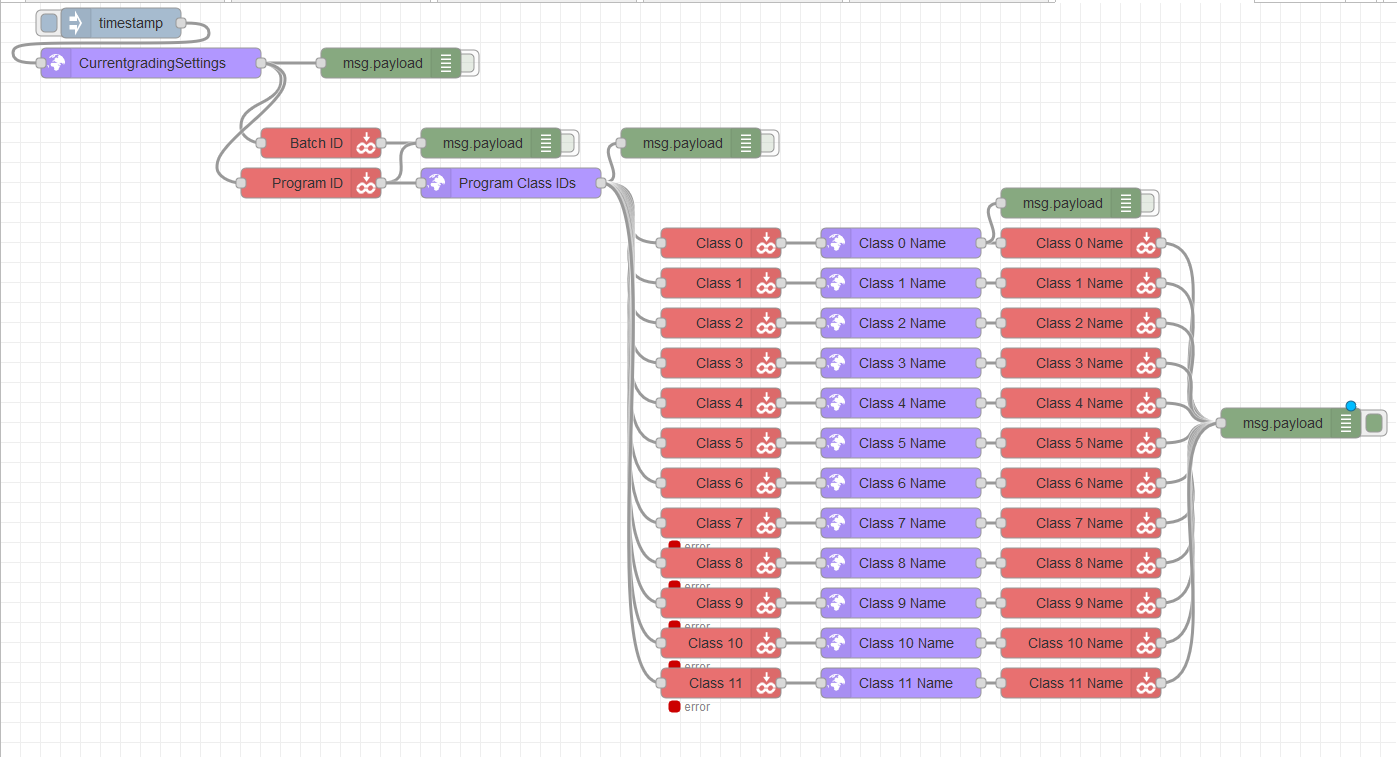
The simplest way to get an array from Node-RED to a groov data store table is to make a single write node for each of the tag’s indices, which is all good and well for small tables but for larger lists this quickly becomes ugly and cumbersome.
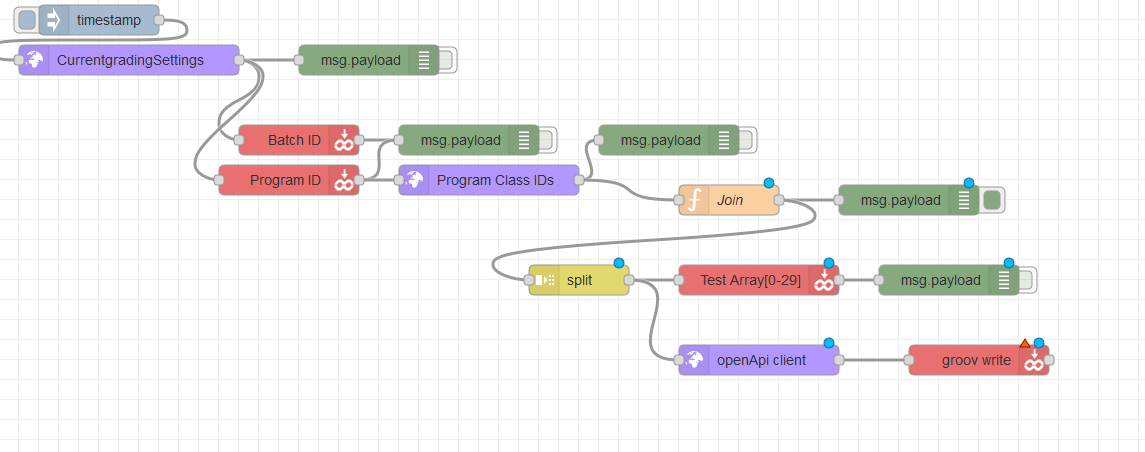
One work around I have found is to use JavaScript in a function node to turn the list into a message payload array of specially constructed objects that gets separated by a split node to write many values, even an entire table, using only a single groov node.
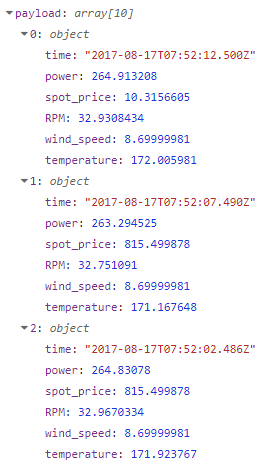
First you’ll need a data store with a table in it. For this example I have a data store NodeRED with a new tag called String_List that can hold a table of 5 strings.
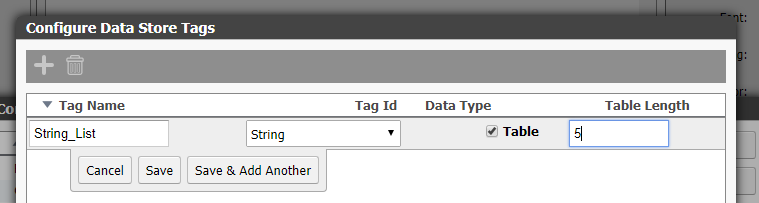
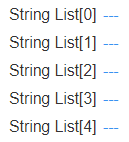
I saved the tag and put 5 value gadgets on a groov page to show the content of each index, in groov view I can see the table is empty:
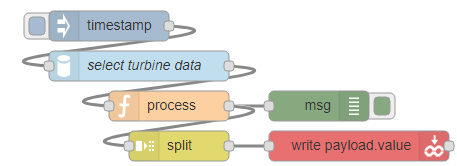
Now in Node-RED I use four nodes: inject, function, split, and groov write, in that order.
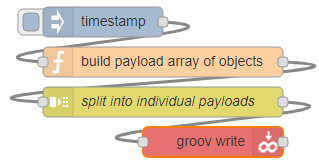
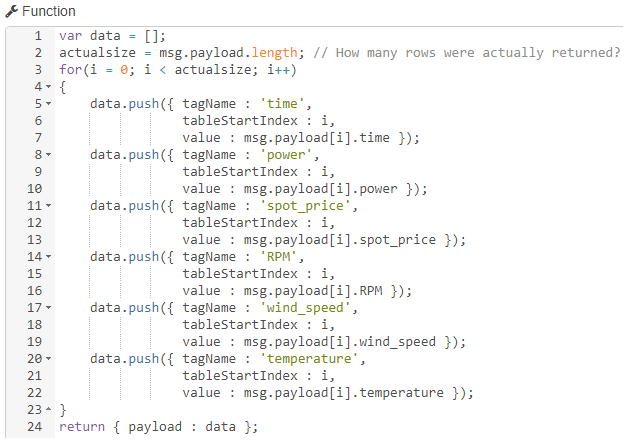
The inject and split nodes can keep their default settings, and the function node uses this code to turn my list sentence into an array of objects:
var sentence = ["Luke","I","Am","Your","Father"]; // Some table/array of data.
var data = []; // A new array to hold the tag, indices, and values for groov.
for (i = 0; i < sentence.length; i++) // Go through the list
{
data.push({
tagName : 'String_List',
tableStartIndex : i,
value : sentence[i]
}); // Each 'data' object will be one groov write
}
return { payload : data }; // This new array is the payload, soon to be split!
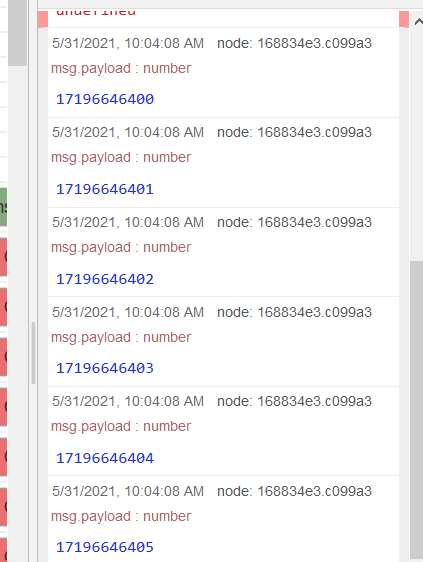
The output of which looks like this:

which splits into:
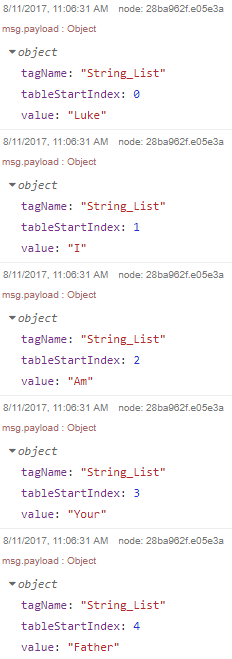
Note that they each take the following form, which will write whatever data (String, Float, Integer, or Boolean) to the tag MyTagName at index i:
msg.payload = {
tagName : 'MyTagName',
tableStartIndex : i,
value : data
} // one "write object"
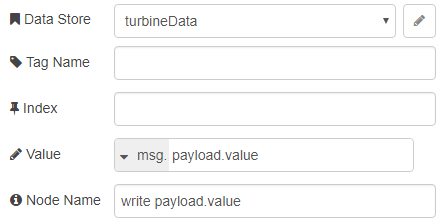
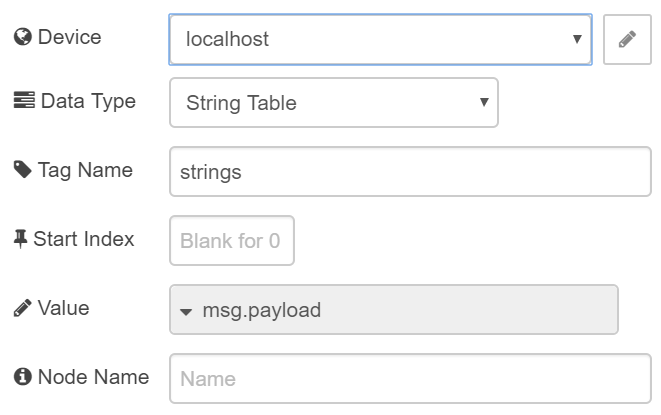
To have the groov node accept this object, set it up the data store (in my case NodeRED), blank Tag Name and Index, and msg.payload.value as the Value.
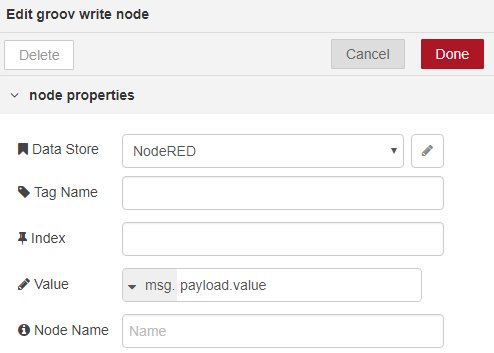
The groov write node takes the rapid-fire stream of payload objects from the split node and writes each msg.payload.value to the groov tag String_List -as specified in the function node- at each index i = 0, 1, 2, 3, with each item from my sentence array.
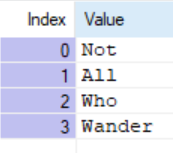
Now I can deploy and inject the flow to see the sentence appear in groov View:
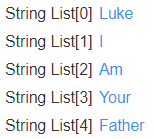
This is a very simple example, it is possible to use a payload array of that basic “write object” format to get all sorts of things into a groov data store with only a single write node!
Happy coding!