If you need your Node-RED flow to work with complex characters like foreign languages for internationalization (or emojis) it can be a bit tricky to know where to start. In this post I’ll break down a few basic examples to explain how to use it and how it works.
The critical function I’ll be focusing on is String.fromCharCode(), it consumes one or more integer or hex numbers and returns the associated character. For example the Unicode character U+1F408 is represented in UTF-16 by hex 0xD83D 0xDC08, which String.fromCharCode() will convert to “”.
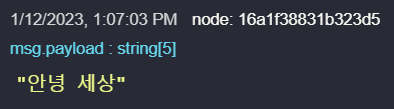
Similarly, String.fromCharCode(0xC548) will return the Korean character 안. For multiple characters, you can simply hand in a comma-separated list of symbols to get longer sentences, such as String.fromCharCode(0xC548, 0xB155, 0x0020, 0xC138, 0xC0C1) which gives the result “안녕 세상”.
If you have your data in the form 0xC548B155 or 0xC5 0x48 0xB1 0x55 you need to do some processing so that you don’t get an error, or four separate characters “ÅH±U” instead of the expected “안녕”.
This is easily solved with a for loop to create 4-character strings and prepend them with 0x, just be aware of the format of your data before putting it into the string function or you will have a lot of trouble debugging your code.
Here’s an example:
var input = "C548B155C138C0C1";
var output = "";
for (var i = 0; i < input.length; i+=4) {
var nextChar = '0x' + input.substring(i, i + 4);
output += String.fromCharCode(nextChar);
}
msg.payload = output;
return msg;
// → msg.payload : string[4] = "안녕세상"
If you end up using this in your application, or have any questions about it, please post in the thread below. And as always, happy coding!
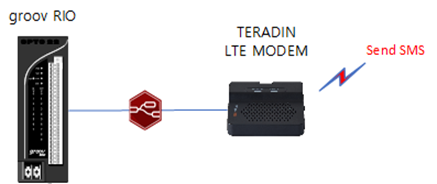
I want to test it on RIO Node-Red by configuring it as follows:
Make message :
msg.payload = ‘안녕’;
Send message using TCP node
The output of the TCP node is transmitted in UTF-8 code,
All Korean LTE modem interprets UTF-8 codes as UTF-16 codes.
‘안녕’ → UTF-8 Code : EC 95 88 EB 85 95
→ UTF-16 Code : BE C8 B3 E7
All LTE modems in Korea is used UTF-16 code to send SMS and UTF-8 code is not used.
I would like to ask if there is a way for TCP Node to output as UTF-16 code.
You need to change the codes you are sending before sending them.
The TCP node will not make the change for you, it just sends what you send it.
Use the function node to change the nodes, then send them out the TCP node.
I want to test it on RIO Node-Red by configuring it as follows:
Make Message :
msg.payload = ‘안녕’;
Connect TCP :
Send message to lte modem using TCP node
The output of the TCP node is transmitted in UTF-8 code
and all lte modems in Korea use UTF-16 code.
I want to ask if there is any way to send UTF-16 code through the output of TCP node…
Example
‘안녕’ → UTF-8 Code : EC 95 88 EB 85 95
→ UTF-16 Code : BE C8 B3 E7
-. Make Message :
msg.payload = ‘안녕’;
-. Connect TCP :
Send message to lte modem using TCP node
The output of the TCP node is transmitted in UTF-8 code
and all Lte modems in Korea use UTF-16 code.
Example
‘안녕’ → UTF-8 Code : EC 95 88 EB 85 95
UTF-16 Code : BE C8 B3 E7
-. Node-Red Used ‘utf-8’ charset and Teradin Lte Modem Used ‘utf-16’ charset only.
-. In Node-red function node, we make ‘Good Morning 안녕하세요’,
the TCP node sends the message to the Lte modem in UTF-8 or UTF-16 charset.
The result, there is no problem in English as in the picture, but the Korean language is broken.
-. Even if the function node converts the message from utf-8 to utf-16,
the TCP node sends the ‘utf-8’ charset to Modem.
-. We want to know if there are any TCP out nodes that can transmit in UTF-16 code.
TCP does not care about the format as I understand it.
You can not change the TCP for UTF8 or 16, they are the same to the TCP node.
Your function block code is not the same as the first post in this thread.
I would re-read the first post, make the change to your code and test again.