While automating the control of a set of pumps, a customer wanted to keep track of how long each had run so far, then decide which pump to turn on next. The next pump to use would be the least-run pump.
The perfect place for one of our many “intelligent I/O” features: the On-Time totalizer! (This comes in both digital and analog flavors, FYI.)
Once a point is configured with that feature, it’ll keep track of the amount of time that point is on… for up to a maximum duration of 4.97 days (when the memory map value for that point will roll over). Neat-o!
This particular customer had a PAC controller in the mix too, and wanted some sample logic for using this feature in his strategy. My solution involves three parts, which happen in a loop.
[INDENT]Part 1: Get & Restart each on-time totalizer for all the pumps we’re monitoring, add those to running totals we’re keeping in a persistent float table.
Part 2: Loop through the elements in that persistent float table and find the lowest.
Part 3: Copy the index of that lowest table element into a value called nNextPumpToUse, and delay for a while before starting over…[/INDENT]
Note in the sample pictured and attached below, I used regular (mostly rectangular) Action Blocks, but I also included some (hexagonal yellow) OptoScript blocks for Parts 1 & 2, for those of you who’d like to see how the equivalent OptoScript code would look.
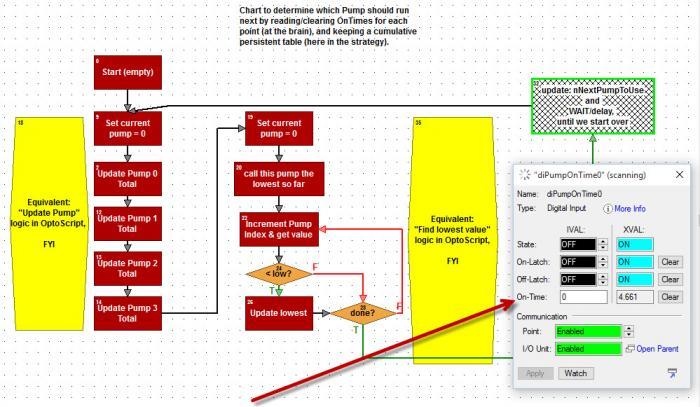
Note: since I’m doing a Get & Restart On-Time Totalizer, and adding those values to a cumulative persistent float in a table, I don’t have to worry about losing the values in the event of a power cycle. I also won’t have to worry about those values rolling over after 4.97 days of on-time for each pump.
Also note that if I maximize my point inspect window there in the debugger, I can see my X- and I-Vals for the (not-yet-cleared-since-last_time) On-Time totalizer values in real-time.
Okay, extra bonus points (and prizes!) for the first to post correct answers to these questions:
- What else does this customer need to do to his strategy to make sure it keeps running if/when the power blips?
- How long should the delay in the loop be, and why is it important for all your looping charts to have a delay?
- Now that those times (in seconds) are safely accumulating in that persistent float table, how long until we have to worry about roll-over (or loss of resolution) there, and how might we make that a longer time?
Do share & totally happy totalizing!
-OptoMary
p.s. Here’s the strategy…
9.4BasicPumpOnTimeMonitor.Archive.D10212015.T122515.zip (5.74 KB)
