In an ongoing effort to figure out exactly why the Groov Rio stops updating / reporting TCP modbus sensor values,
I’ve been tasked with causing repeatability with the error. Easier said than done. PLC side, I can interrupt the TCP Modbus, which causes the same issues. Rio side, I have no idea. So i was thinking our IO demand may be too great. but it TCP Modbus, doesnt fail reliably, it just seems to fail randomly.
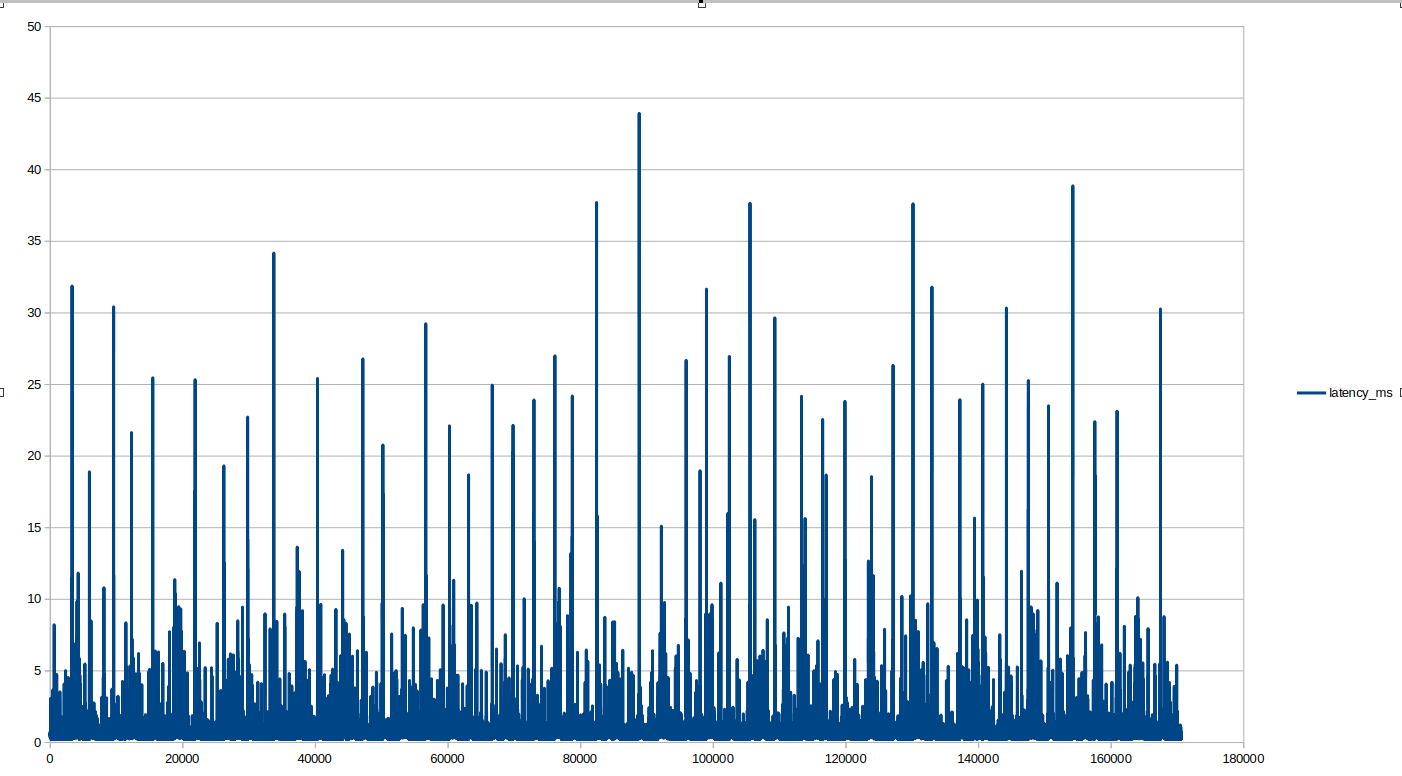
So I set up a query, to poll modbus every 10ms, 1ms, 100ns. Well, latency seems to stay about the same on average, … about the same as the Main Scanner polling interval? something like 12ms, but with occasional , predictable spikes.
100ns is excessive? YES! but I cant wait around for this thing to fail randomly, and try to catch it being BS. So I’m willing to max this thing out a bit, Outside of blasting the Rio with EMP, I haven’t been able to deterministically cause the modbus to “stick”
Well I guess its not latency and timeouts. Probably not CPU Maxing either.
So Im thinking that whatever the system does to unload the CPU, maybe the TCP Modbus doesn’t wake the system in the same way other services like OptoMMP or a ping might.
maybe the CPU goes into an idle state. Maybe I should take it the other route:
poll once every 5 minutes or so.
I would recommend contacting our Product Support team as well, they can assist you with direct troubleshooting.
Phone: 951-695-3080
Email: support@opto22.com
What is the Modbus client that you are using to access the RIO? Is anything other service running on the RIO? Have you looked at the log files for anything out of the ordinary?
Hi Greichert,
I started there, and its on going. Figured I would poke the community as well.
Seems at least a few folks have encountered the issue, not sure if anyone has a direct cause.
Im talking with another member in my team about it, who seems to think UDP spamming broadcast addresses keeps the RIO alive. .. which I mean, you know how it sounds.
But I have to look in to everything now, because my best guesses were not right.
When we first encountered this issue 9 months ago,
we concluded that the (a) source was Electro Magnetic Interference, effecting the Modbus. Using a grill lighter I was at the time fairly reliably triggering the event where
IO gets stuck in the last known state, and reports inaccurate values.
Updating the firmware did seem to help, but in our deployments, a compressor contractor when closing was measured to be outputting 2000uT, and the field issues remained. In part, due to our in field network configuration:
[PLC]→[Rio]→[HMI]
which makes updating the Rio Firmware virtually impossible remotely.
Well back in testing, I took a microwave transformer, and cut off the secondary winding, to create a EMI generating 2000uT. Frimware update or not, I was able to fairly reliably interupt the TCP Modbus Connection.
OK sure, its undesirable to have the EMP, but there not much I can do about that remotely. The real issue we have is that the TCP Modbus retains and reports sensors as the last values read, and never re initializes the connection. Every thing fails. Our job as controls engineers is to make sure when it fails, it does so safely.
Enter OptoMMP.
Well it was a pain in the butt to write PLC code to generate and send OptoMMP commands, but it was ultimately do able. When OptoMMP fails, from an EMP,
the values are not retained. This allows our other systems to process the state, and programmatically in a more safe and reliable manner.
This post would be better with pictures.
No more Stale Values.
1 Like
Ok, well… it seemed like was working.
but the problem has re emerged, as ugly as ever.
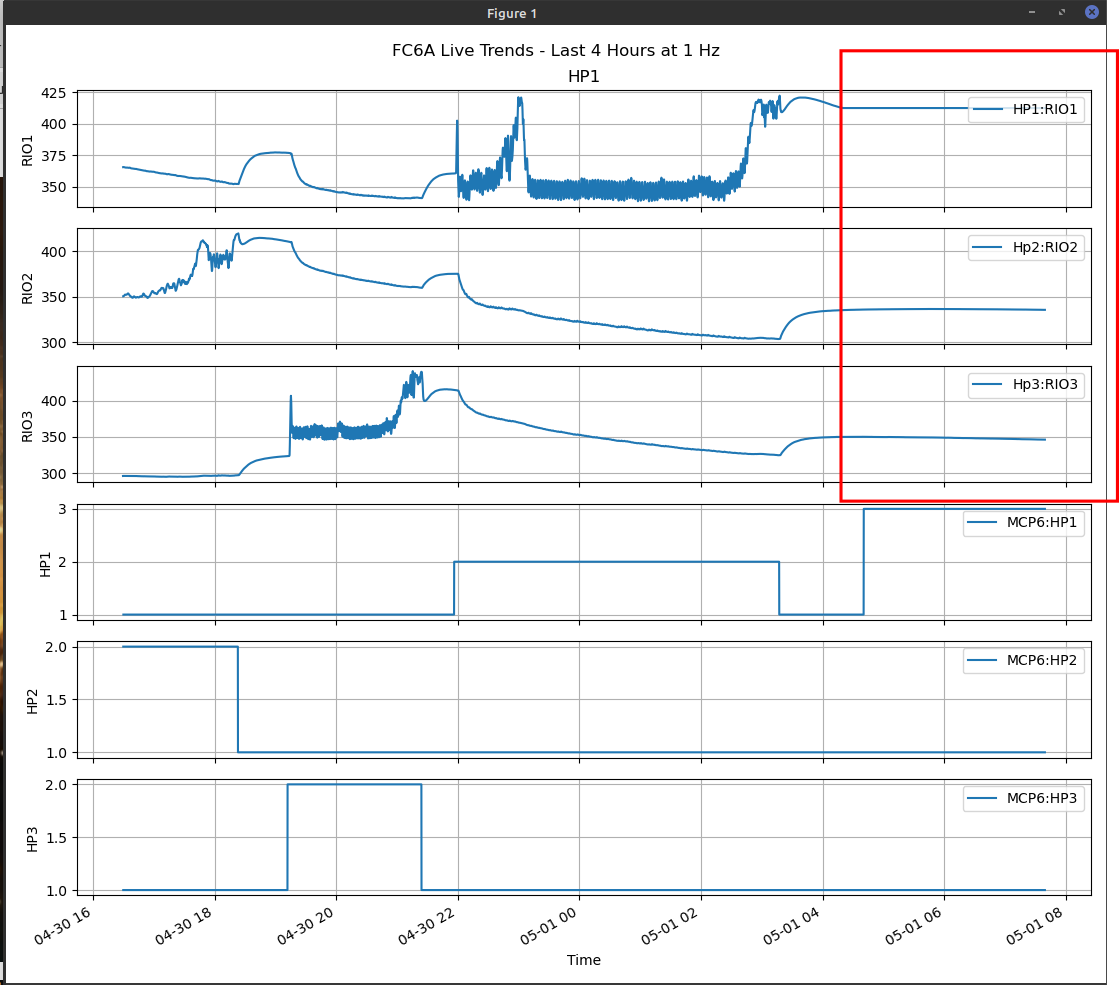
We have implemented code using OptoMMP,
and here it is again. here we have the same static values issue.
This plot is a live monitor Hp1,2,3 Rio 1,2,3 are readings of the sum
(read from our PLC) of the analog inputs on the Rios.
When this event happens, our units may have unexpected operations.
IDK, Im starting to think its the actual hardware. We have observed this on both
Modbus, and OptoMMP readings of the analog sensors. The outputs do the same
Frozen condition, but those aren’t part of what I am monitoring here.
Have you tried triggering the issue with the field wiring connector disconnected to rule out induced voltage/current on the field wiring that is going above specifications on the RIO?
in the lab, yes, and it can be done.
this specific set of units is about 3000 miles away, so…
Low Voltage routed separate from the higher voltage stuff.
EMI is just a testing approach for creating a problem I’m observing remotely.
Its hard to patch a fix without knowing the exact cause, or having any means to duplicate the behavior. The pattern, might emerge in a day, week or month, it will happen eventually. It doesn’t actually seem to matter if the high voltage equipment is running or not. in the most recent image, the units aren’t running when the issue began.
Modbus over TCP has provisions to deal with corrupted data from EMI/noise.
The CRC check with Modbus was removed with TCP, but the TCP protocol handles all that error detection (which is typically abstracted away from most applications). The socket managed by the client might be returning errors if this was the case.
If you had the ability to look at the packets or socket error responses, I believe it might help a bit with your troubleshooting.
In our panels, we have a ton of EMI to deal with from large VFD’s. We run our own Modbus client, but Modbus communication issues usually present as timeout errors that we monitor. Anecdotal… but I have also found that some devices respond poorly to a barrage of re-connection attempts.
Sorry I do not have a solution… If the issue is EMI at the RIO’s, the one thing that has worked consistently for us in the past (albeit, on the RIO EMU’s, EPIC’s, and other controllers) has been better isolation from other wiring/devices and shortening wire leads in the enclosure to the controller. All of our noise issues we have experienced in the past typically appeared as intermittent module-level problems, with Modbus TCP issues being fairly rare.
-Peter
Eh, I think I have the issue worked out.
The sensor bus, fpga, whatever, encounters some issue where it buffer overflows, or corrupts its bit stream, then it stops updating. The kernel has no way to detect this, so it continues to report values that are not actually updating.
Then the services, (whatever, modbus, OptoMMP,…) get and report wrong data. Nothing seems to check the sanctity of the results.
So then you read it, and interpret wrong data.
but you notice, and reset your connection to the device, and it starts working again.
This works because the session close causes a flush, which resets the kernel process, and possibly the controller itself.
So then, the solution for us is to detect the fault where sensor readings become stale, and reset the connection on the PLC (in our case), and reconnect. this rectifies the issue until the next time it occurs. But this is a programmable solution, that doesn’t require rebooting the Groov Rio, or reloading the PLC program, or getting a human to pull the Ethernet cable.
the probability that you have an analog device with 0 noise is 0.
Since panel design, grounding design, and system design is not part of the discussion, it still sounds like emi. This is not to say that the RIOs could have a problem, but my experience with Opto has been very good in regards to EMI. There are no processor systems out there when enough EMI of the right kind is present, it will fail.
Also, check the input power to the RIOs, although there is a power supply/regulator on the input power, dirty power can still drive past this and cause corruption.