I never usually do anything extensive with strings, but this project is pretty heavy on it.
I am reading a text file from the sdcard0. All that goes just fine, but the problem is the CR/LF that is in the CSV file I am reading.
Now the default EOM is CR, but since the LF is after that, of course as expected it doesn’t get dropped and ends up at the beginning of next line. Although I managed to program around this in my parsing routine, it also becomes a problem at the end of the file, where the ReceiveStringTable command sits and waits for the next character (waits for timeout) instead of ending the file read.
Of course I tried to set the EOM to 10, and that doesn’t work…so what am I missing here?
Ok, to finalize this thread, it is official, in spite of numerous references referring to setting an EOM to LF in the user guide, this is apparently a no, no. It simply doesn’t work.
The workaround is to open the file in a hex editor and remove the LF’s throughout the text doc before trying to read it…well that kind of defeats the purpose, right?
So I guess what Dave was trying to tell me was just ignore it…and deal with it. I have a working solution, I just hate band aid code…
Do you know if this is something to do with the ReceiveStringTable command or specifically with reading off the sdcard? If it is the command, it should be possible to do the same thing with different commands (though more code involved).
Well I can’t say for sure, however, looks to me like the receive string command is doing what is expected. The problem appears to be (and engineering suggested) that the problem is with the Set EOM command. It doesn’t appear to be able to respond to an LF character, in fact, when I set the EOM to LF, it doesn’t change the result at all.
Engineering suggested removing the LF from the file, but as you can imagine, that’s not at all practical.
At this point I’ll live with it because it is a workable solution to simply ignore the LF at the beginning of each line, starting with the 2nd line.
On the other hand, what I suspect is that the file takes longer than necessary to load (65 seconds for 987 lines with around 170 chars each). If I am right about the time to load, my guess is that the command waits for a longer timeout period than normal, because it detects the CR on the last line, then checks the next line, sees the LF and then waits to see more characters. As a result of setting the LF, the error code is -40 (more chars expected) versus -39 when the CR is set as EOM (timeout). I had set the timeout to 2 seconds, and I don’t believe I saw a diff. In either case, it does the same thing, regardless of which EOM you set.
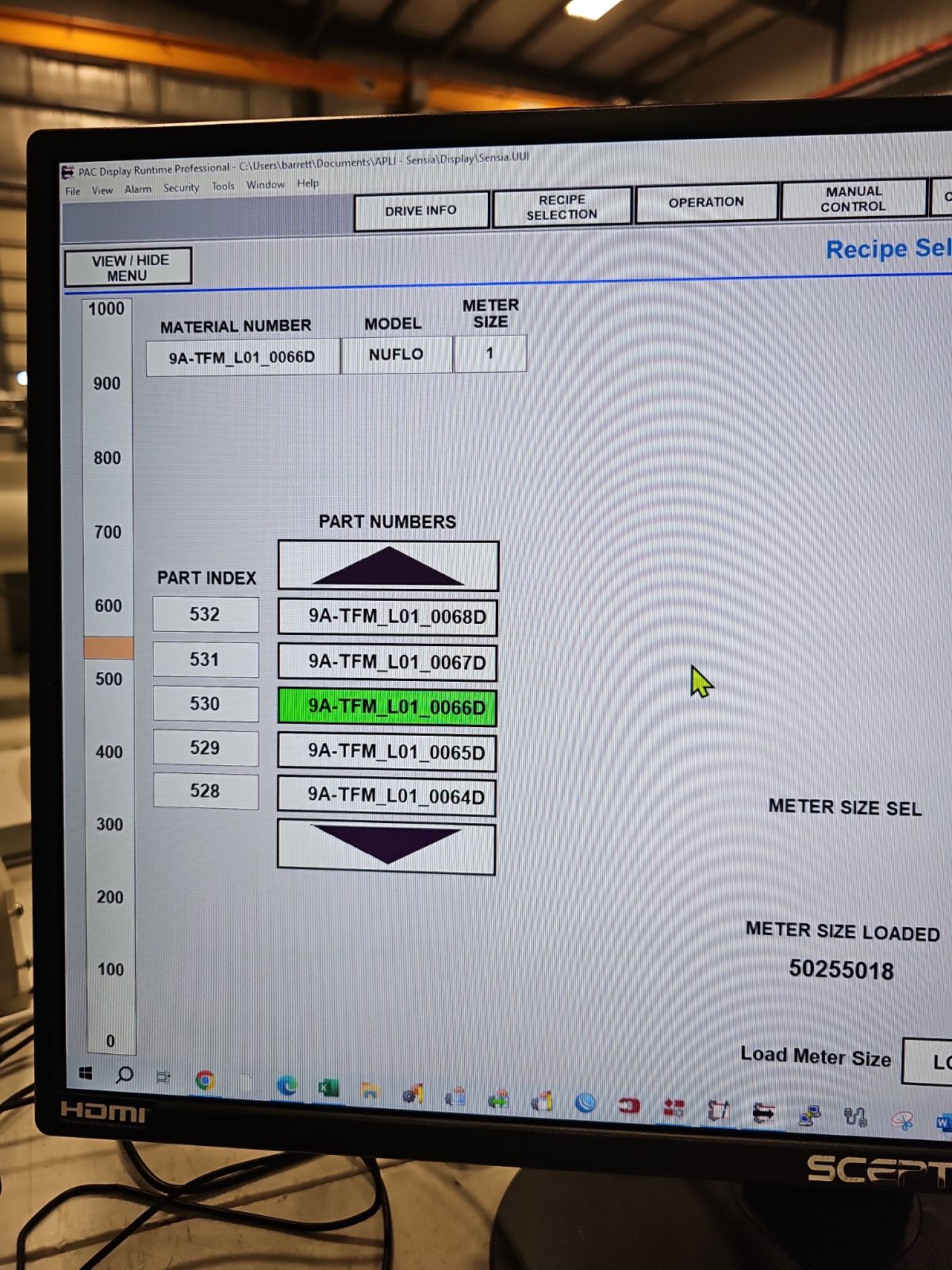
I did, however, succeed in creating a system by which you can initiate a file download into a 1000 element stable and then that gets the first column parsed into another stable, which is then used to select the part number on a PD screen. Then each time a new part number is selected, it highlights that number, and compares it with the last record parsed part number, and if different, it parses the new part number record of 34 columns of data into variables, ready to process the next flow meter.
So instead of parsing all 1000 records, I only parse the one that is selected and it only runs the parsing script (500 lines) when new part number is selected.
I ended up writing the whole parsing script out instead of looping it because I have a mix of ints, strings, and floats and not in order either. This pic is of the beginning of the product select page, the first of 34 columns at the top. The slider allows for fast search viewing, and then the arrows allow for an incremental search which accelerates as you hold the button down. I provided 5 part numbers for viewing to ease the search process.