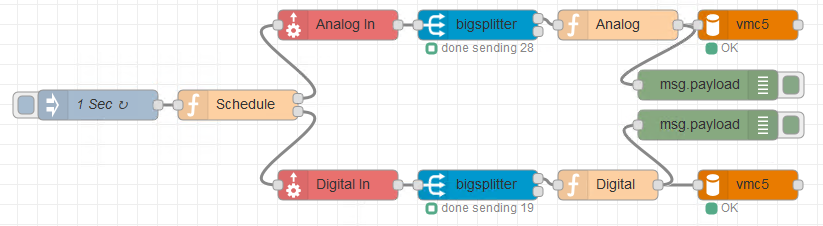
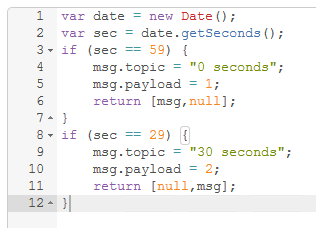
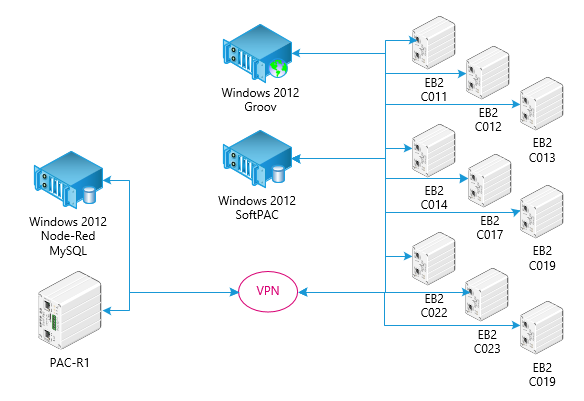
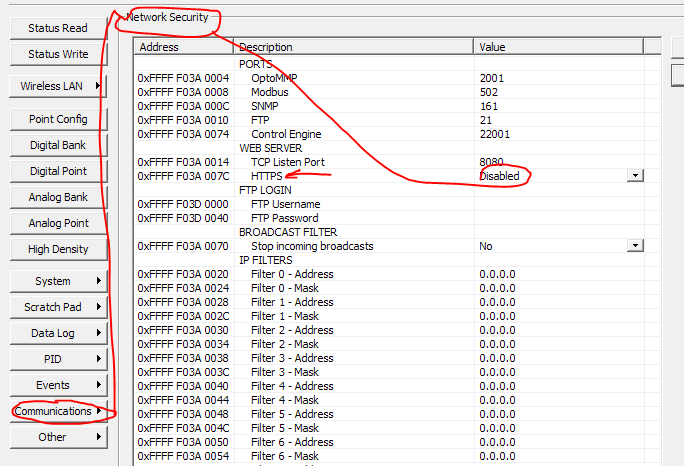
I’ve had better luck splitting my reads in NR of multiple tables from the running strategy. I built a ‘Scheduler’ to trigger multiple reads every five minutes at five second intervals.
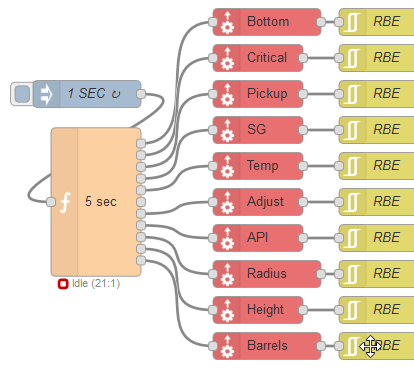
Javascript:
var date = new Date();
var sec = date.getSeconds();
var min = date.getMinutes();
var m05 = date.getMinutes() % 5; //every 5 minutes
if (m05 === 0) {
switch(sec) {
case 0:
node.status({fill:“green”,shape:“dot”,text:“Output 1 - 00 Sec”});
return [msg,null,null,null,null,null,null,null,null,null,null];
case 5:
node.status({fill:“green”,shape:“dot”,text:“Output 2 - 05 Sec”});
return [null,msg,null,null,null,null,null,null,null,null,null];
case 10:
node.status({fill:“green”,shape:“dot”,text:“Output 3 - 10 Sec”});
return [null,null,msg,null,null,null,null,null,null,null,null];
case 15:
node.status({fill:“green”,shape:“dot”,text:“Output 4 - 15 Sec”});
return [null,null,null,msg,null,null,null,null,null,null,null];
case 20:
node.status({fill:“green”,shape:“dot”,text:“Output 5 - 20 Sec”});
return [null,null,null,null,msg,null,null,null,null,null,null];
case 25:
node.status({fill:“green”,shape:“dot”,text:“Output 6 - 25 Sec”});
return [null,null,null,null,null,msg,null,null,null,null,null];
case 30:
node.status({fill:“green”,shape:“dot”,text:“Output 7 - 30 Sec”});
return [null,null,null,null,null,null,msg,null,null,null,null];
case 35:
node.status({fill:“green”,shape:“dot”,text:“Output 8 - 35 Sec”});
return [null,null,null,null,null,null,null,msg,null,null,null];
case 40:
node.status({fill:“green”,shape:“dot”,text:“Output 9 - 40 Sec”});
return [null,null,null,null,null,null,null,null,msg,null,null];
case 45:
node.status({fill:“green”,shape:“dot”,text:“Output 10 - 45 Sec”});
return [null,null,null,null,null,null,null,null,null,msg,null];
case 45:
node.status({fill:“green”,shape:“dot”,text:“Output 11 - 50 Sec”});
return [null,null,null,null,null,null,null,null,null,null,msg];
}
} else {node.status({fill:“red”,shape:“ring”,text:“Idle (”+min+":"+sec+")"});}