Hello everyone! We’ve been considering implementing a historian in a plant where we are running around 30 SNAP PAC R1 and EB1 controllers with approximately 1000 tags. We need to store all the tags with 1 second resolution. So far, we’ve been storing historical data in CSV files using the PAC Display function. However, this system is becoming cumbersome for performing any type of data analysis.
Some options we’ve investigated include Ignition, Canary, Opto Data Link, REST API, InfluxDB, and Grafana. We still have several questions. Budget-wise, we could choose any of these alternatives.
Our first question is: to obtain data from the R1 and EB1, is there a preferred method among the options? Between Opto Data Link, REST API, MQTT, or directly using the Cirrus driver with Ignition, what are the advantages of one over the other? Is all data exportable from the controllers through these methods? I’m particularly unsure about data running on the I/O, for example, whether all PID information can be obtained.
Regarding data analysis capabilities, what are the advantages or disadvantages between using Ignition, Canary, or simply exporting to a time-series database and visualizing with Grafana?
Is there any advantage of adding Groove controllers to the network as kind of bridges to export the data to the historians?
I know this are very broad questions, but just hearing from your experience and where to look for more information would be great.
I think it would help us toss around ideas if you could flesh out what you are looking for in regards to the historian.
For example, you mention Canary, great graphing for sure, but that’s about it.
You also mention Ignition, not only can it do graphing, but also alarming and reporting.
So my question is, what sort of data analysis are you looking for?
Hey, @gchase and @grant1 you guys have some experience in this sort of thing, any thoughts, questions or comments?
Thanks Beno! Initially providing plant technicians with the option to easily graph any of the tags would already be a significant improvement over the current CSV files. It’s important that the graphing software is fast and allows navigation between different dates and zoom levels without delay, even when handling large amounts of data. Another requirement is the ability to export portions of the data to Excel for further analysis. Alarms and reports are not something we’re looking for immediately, but they could be very useful in the future. I understand that, of all the solutions we’ve been considering, Ignition is the most comprehensive, and given that we have the budget to implement it, perhaps it would be best to focus the implementation effort on that option? Are there any drawbacks to choosing Ignition over other alternatives, aside from the higher cost? Any other options that you can think of apart from the ones mentioned?
Great topic and one which I am happy to weigh in on…
Our plant has groov EPIC and Rio units (no SNAP PAC stuff). On the EPICs we are running PAC Control Programs, while the Rio’s are used mainly to grab various I/O info (temperatures, on/off status, etc.). We do not have 1000s of tags on our PAC Control programs, but we do have perhaps 100 or so, but I do not think the number of tags to be stored with 1 second resolution should be an issue.
Overview:
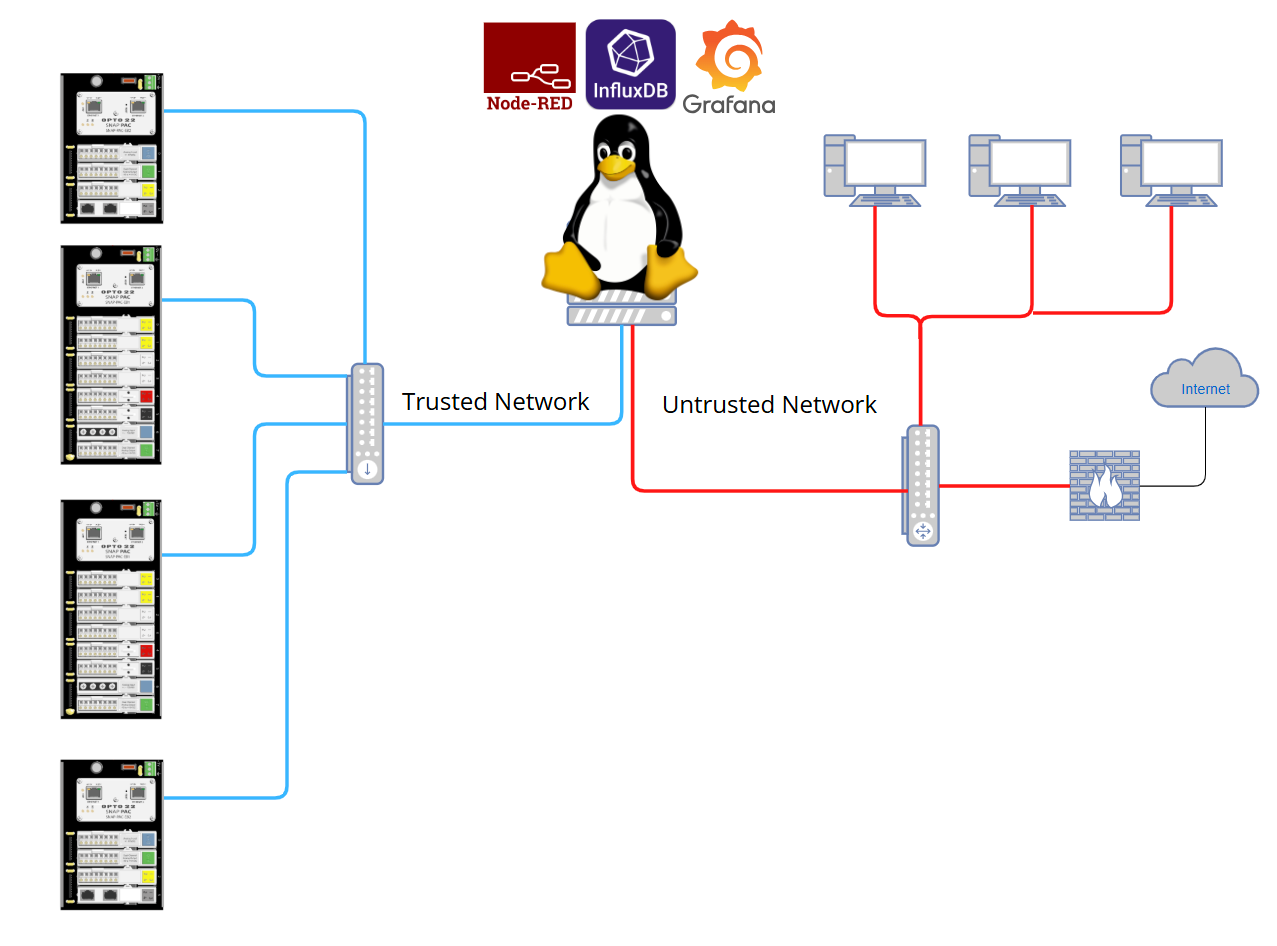
groov EPIC & Rio units do their thing and every bit of info they have is accessible via Node-RED. We use the InfluxDB node to send our data to InfluxDB. We also have MODBUS data from controllers, etc. and locally generated MQTT data being grabbed via Node-RED and being sent to InfluxDB. ↓
Field values and tags are ingested into on-prem InfluxDB (v2.7) with values every 1 second. ↓
On-prem Grafana OSS (v. 11.2), running on the same Ubuntu server as the InfluxDB, is used to display / chart and alert users on anything going wrong. Approx. 25 users are viewing Grafana at any time and there is no latency or delay.
Nobody but me goes into InfluxDB. That’s just the database that nobody needs to look at. Everyone (even low tech people) uses Grafana and finds it easy and intuitive using the time selector. It’s easy to build different dashboards, charts, etc. for different needs. We regularly destroy and rebuild dashboards and are continuously making things better.
We have about 5 years of data in InfluxDB and have no trouble querying large spans of data over this time period. The queries are all written in Flux and are very performant. The key is to very carefully plan out your fields and tags. This video is ~8 years old, but I still found it valuable to help plan out everything.
Sorry I’m late to the party, I was out of the office this week, I am happy to discuss this also… I guess you can call me grant2
Our approach is similar to what @grant1 has described however, we do have many SNAP PAC’s in our system(s) as well as PLCs from other manufacturers.
We also use InfluxDB and Grafana as our data visualization stack running on Ubuntu server. We use two methods to move data to InfluxDB; Node-Red via the InfluxDB node as grant1 has described and MQTT via Ignition Edge using the Cirrus link driver and MQTT transmission to Telegraf, which ingests data to InfluxDB.
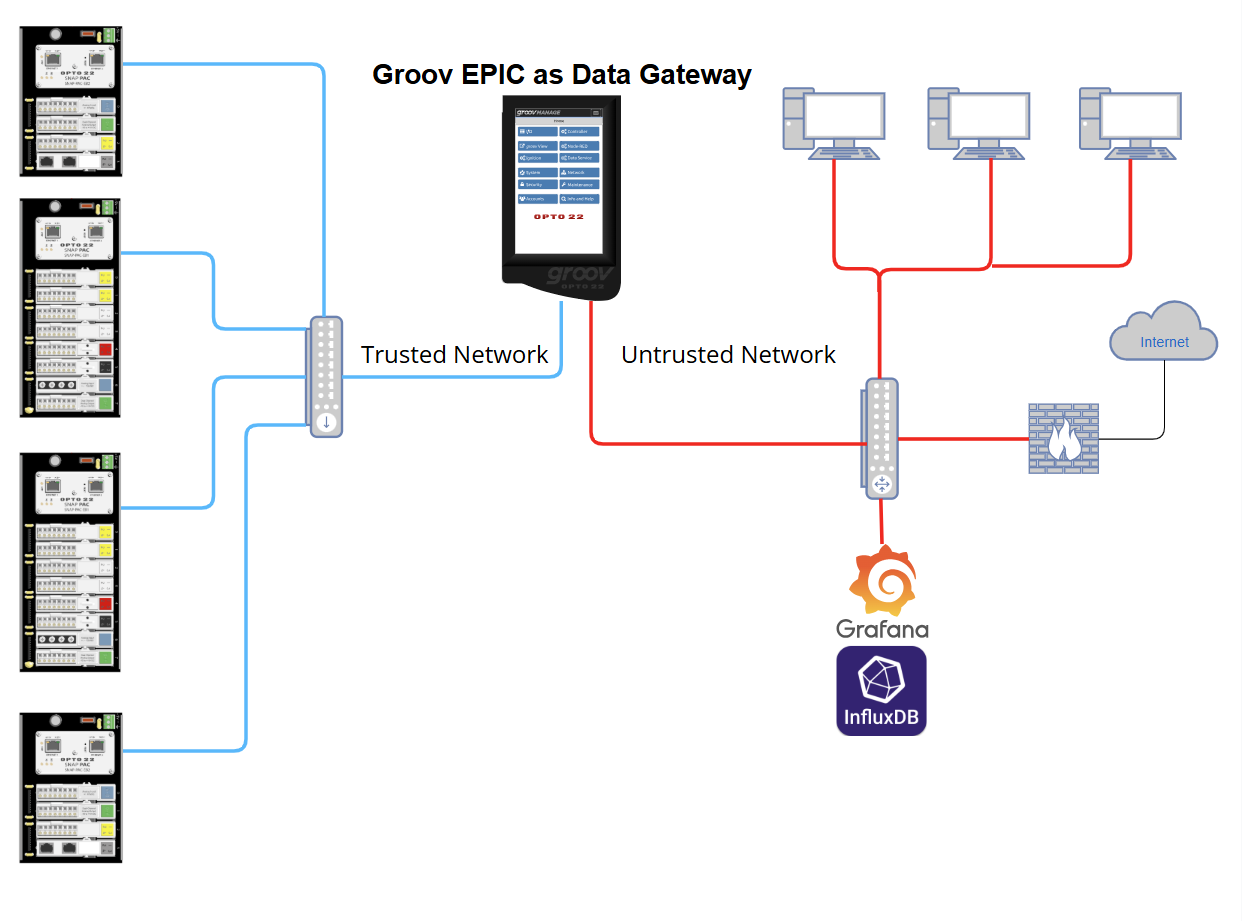
We use the EPIC as a data collection gateway in both instances.
Both of theses methods are reliable and both have advantages and disadvantages which I will attempt to outline.
Using Node-Red:
(Our approach is nearly identical to grant1’s but I will elaborate on some of nuances)
For each PAC control strategy a series of PAC Control nodes, one for each data type: int32, float, etc., reads ALL the tags of that type in a batch. ↓
The batch data can be parsed and manipulated at this point to adjust and tag names or add data fields for InfluxDB (more on that later). ↓
Batch write to the database using the InfluxDB node.
Advantages:
Small foot print
Few dependencies
If your tag names are consistent, I hope they are, and your batch is set up correctly then it can be very scalable and a new tag if added to the PAC Control Strategy will be added to the batch read and write to the database so, the new data point is added to the historian automatically.
Disadvantages:
If your tag names are not consistent then there will be lots of “hand”manipulation of tag names for each case.
Depending on your network topology true 1 sec resolution my not be possible due to the many layers of communication inherent with HTTP/HTTPS and REST API. But you can get pretty close….. Our system has a few wireless control points that need more time due to network latency.
Care must taken with polling a SNAP controller too fast as it will become impacted and begin timing-out your requests. Because each data type must be called one at a time it may be 3 to 5 seconds before you can call all the floats again. (For more info on deployment practices see this post on Optimizing Node-red)
Using Ignition Edge, Cirrus Link, MQTT and Telegraf:
(Ignition is a extremely powerful platform. I want to preface this by saying that this is a very different way to use Ignition Edge as I am using it essentially “headless” with no HMI and this use case was originally employed due to our need to get data from non-Opto PLC’s)
Using Ignition Edge and the Cirrus link diver for SNAP controllers tags are added to a designated MQTT transmission folder with in the Ignition designer. Cirrus Link MQTT transmission publishes tags to the MQTT broker using the Sparkplugb protocol. ↓
The Telegraf configuration subscribes to MQTT topics filtering them using the desired Sparkplugb topic namespace and wildcards, decodes the google protocol buffers, formats the namespace for value tags and fields, captures the value and passes it on to Influxdb.
Advantages:
The Cirrus Link Divers, I believe @beno correct me if i am wrong, use a different method to communicate with the SNAP controllers. It’s faster than REST so 1 sec resolution is more attainable.
Using Ignition’s extensive driver library, you can connect to most an PLC.
Disadvantages:
More dependencies than the Node-Red method.
Debugging Telegraf is much more difficult, can be downright painful.
Lots of set up to only use a small part of Ignition edge’s capabilities.
Grafana OSS
Now that the data is in the database we use Grafana Dashboards for all operations staff.
I completely agree with grant1’s statement below.
Grafana is also a very powerful tool, 1 sec resolution works great up to a certain time window but…. if you try to look at 1 years worth of data @ 1 sec resolution even the most powerful tools can falter. To give operators control without having to know how to write a query we use what they, Grafanistas, call dashboard variables to make query’s more dynamic. We have a data resolution drop down on each dashboard that allows operations to adjust the interval from 1 sec all the way to one hour if needed. Then you can use the mouse to select a portion of the graph to zoom in, then you increase the resolution.
This is a native feature in Grafana. Once you have the time window selected you can export individual graph panels as .csv with excel headers.
Ignition is an amazing product, and yes very comprehensive for the industrial control space. However if you are not planning on using all the tools ignition has to offer, HMI, Alarming, Reporting, etc., I would suggest getting an EPIC, PR2 to give you the firepower to handle the 1000 tags you want, and a Linux server to run InfluxDB and Grafana. Ignition has a stepper learning curve compared to Grafana when building dashboards for data analytics.
In regards to InfluxDB, grant1 is spot on!
This is essential as it will dictate how you retrieve your data.
That’s plenty to chew on for now so I’m going to stop here.
My setup is very similar to grant1. The main difference is that I run nodered on a separate server and not on the Epic hardware. Also, I program the Epic hardware using Codesys and publish the variables via OPCUA. From there I use a few nodered nodes to subscribe to the OPCUA tags and push them to an InfluxDB database.
Before I moved to InfluxDB, I made a test program in codesys that just ramped ~1000 tags to see if how the database would handle it. The influxDB server did not even really see a blip on usage. Influx can take in a large amount of tags/sec.
Everybody seems to love Grafana where I work. I never have heard a complaint about it.
I use Ignition only for HMI Vision. It seems to work well. It just takes some time to create your UDTs to have an efficient work flow. These days I use a lot of IPCs where I install Debian and the realtime kernal patches and run Codesys for control and the WebVisu HMI. It is nice that I do not have to keep a tag list in sync with the control code and Ignition. I wish the Epic hardware would have Codesys WebVisu available.
Another question we have is that currently, our network, where all the SNAP PACs are connected, is completely disconnected from the internet. I understand that if we implement an InfluxDB or Grafana database, they would run on this same network, but we would need to provide external access to the network for users to view the information. What recommendations do you have for providing such access?
I’d run a DMZ off your firewall/router or perhaps a dual NIC PC and keep your SNAP PACs/EPIC/RIOs offline and only expose the second network interface to the external / users.
@edom I want to help clarify some details based on your comment below:
InfluxDB AND Grafana, not “or” you will need both, as Grafana does not store your data (it does have its own database for internal functions like user accounts and such.)
If you do not need to access them from the control network InfluxDB and Grafana do not need to reside on the control network.
Sounds like your looking for Network Segmentation from the control network.
If your end users will only be accessing Grafana from a different network then an easy way to accomplish this would be Physical Network Segmentation, utilize a groov EPIC and its Dual NIC’s!
Ethernet port 0 for the Control “trusted network” and Ethernet port 1 for the Enterprise “untrusted network”. EPIC will collect data from all SNAP PAC’s and push that data to InfluxDB and Grafana on the Enterprise network.
Here is a basic diagram
Don’t forget that you may want to also run Ignition there as well.
For device drivers, some local visualization, reporting, alarming and if its on the edge, SparkplugB store and forward.
The EPIC will give you a power fail safe file system. The PC should be Okish in that regard (and don’t get me started about UPS maintenance), but keep it in mind.
Lastly, the EPIC is -20 to +70 C. Some PCs will do that, some only with a fan.
@grant1 Looking at a little project that detects motor armature core defects on a production basis. I could use Excel and stop there, but I was considering getting into Grafana/InfluxDB.
Do I gather that the InfluxDB 3.0 is the place to start and the Grafana OSS?
@Barrett Actually, as much as I have enjoyed using InfluxDB over the years, the whole v3 release has been confusing and chaotic. I found Arc database to be better and easier, and have even collaborated a bit with their founder. They have full compatability with Grafana and offer both an on-prem and cloud-hosted database. More here: https://basekick.net/
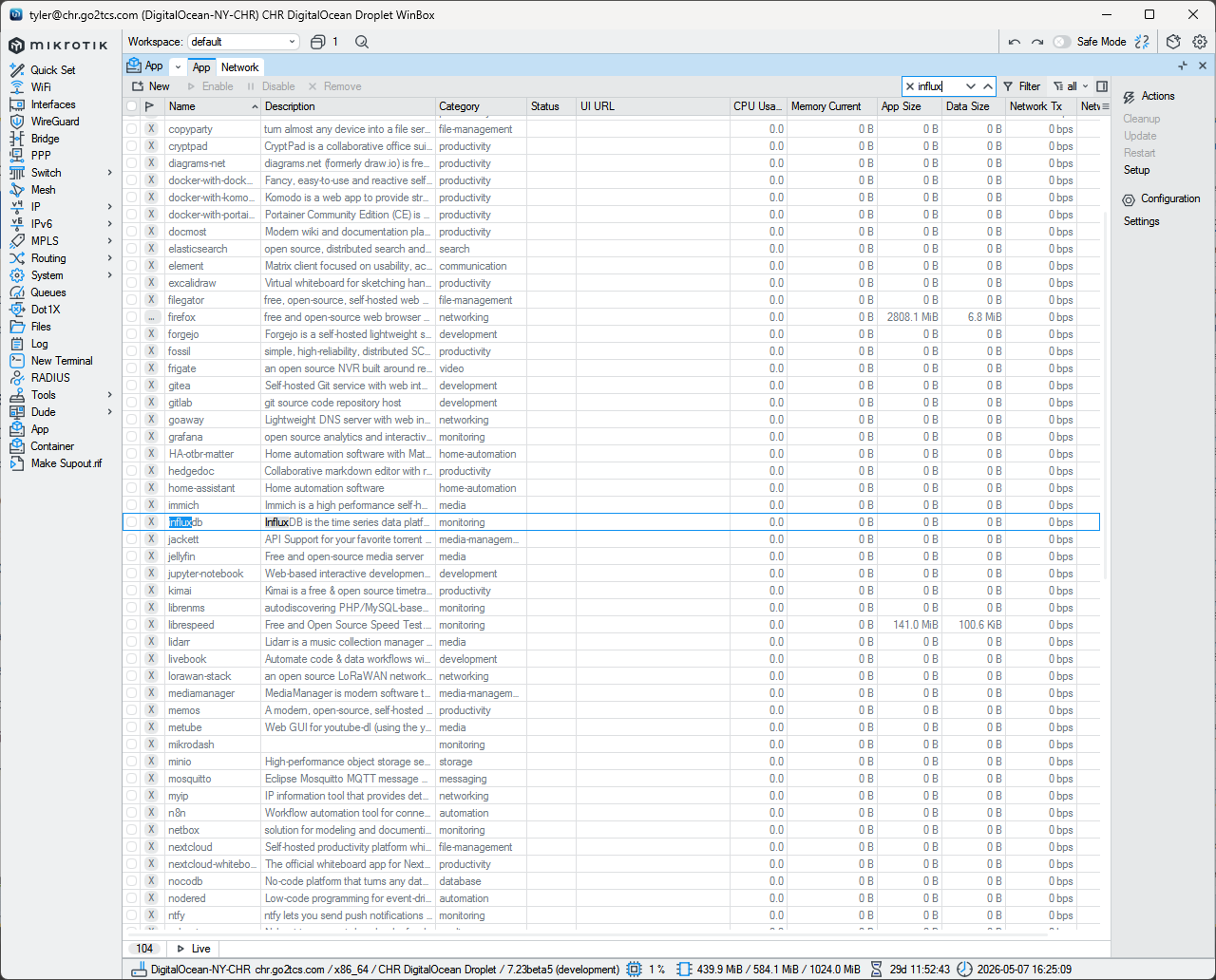
Here’s a thought, I have a Mikrotik guru that I use for any more complex router setups I might need, and he texted me this image of a list. Apparently this is a partial list of the 1 click install apps you can run on a Mikrotik arm64. There are a number of arm64 appliances that they sell, including a HAP Be3 Media which has 2 - USB A, 1 - USB C, and a MicroSD slot. It runs containers and can even run raid on the flash drives. I did not see Arc, but it does have quite a list. So in theory you could run Grafana, Influx DB, and have a Raid backed set of drives all with 2.5 ghz ports on this mini file server for $179. Here is the link: MikroTik · hAP be³ Media