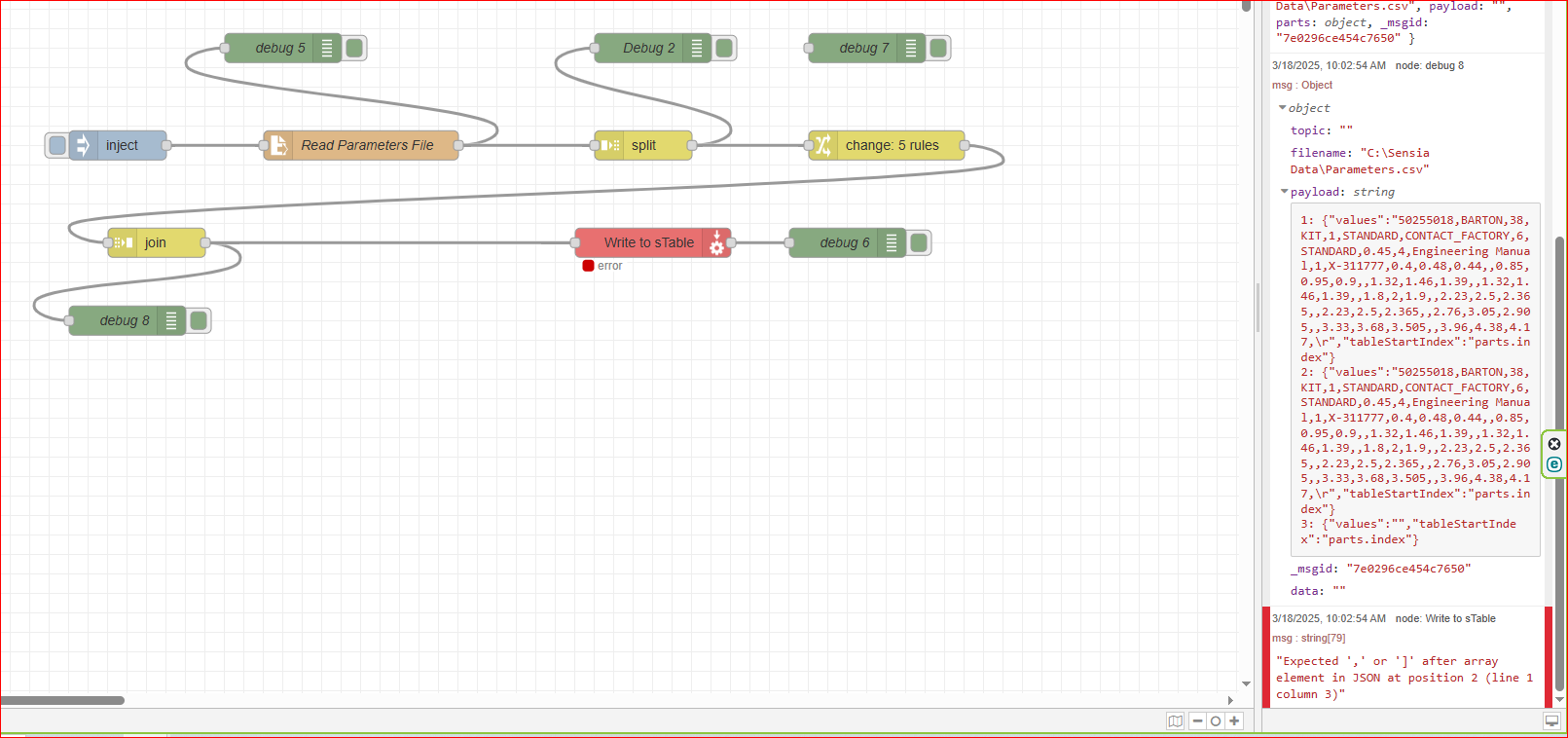
Can we take it that the file read to PAC String table is working?
Can we take it that the file read to PAC String table is working?
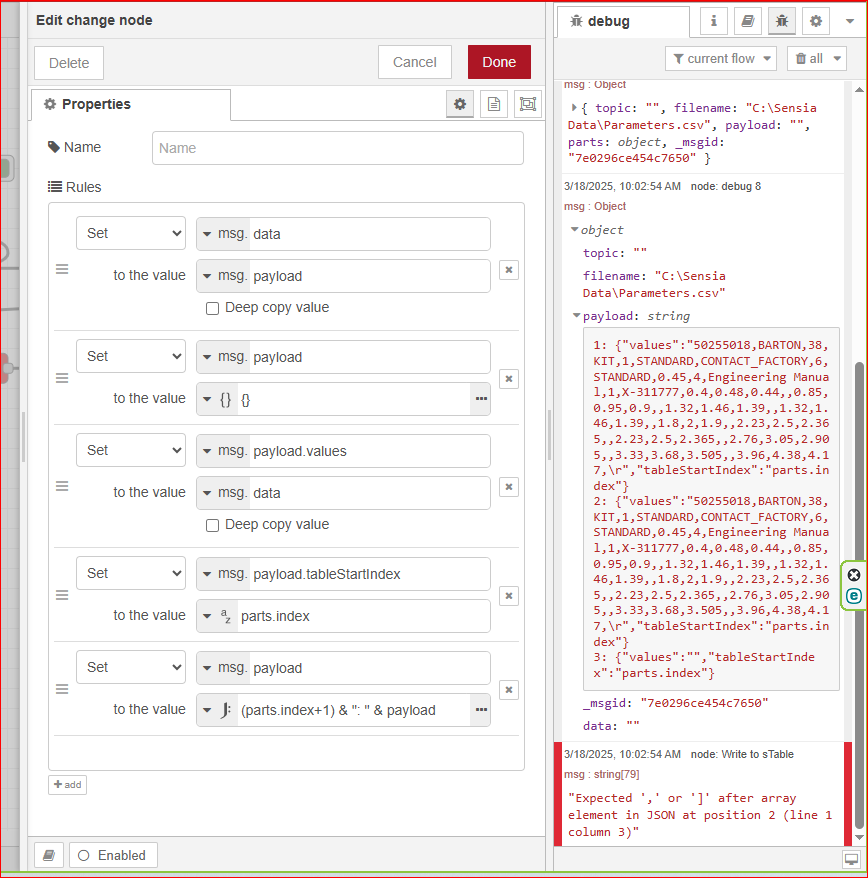
No, the write node errors as it was set with “not valid json”. So I set to Value, and what you see is what you get.
Maybe I would better understand this if I could see some of the underlying code.
So, I see that you are defining the strings in the elements as msg.data, but how does the indexing get applied to that?
And, what do I set the write node to examine, msg.data?
When posting your exported flow, please put it in ticks ` so that it doesn’t lose formatting — I can’t import that as-is.
With that said, you’re on the right track with join. I had it misconfigured when I tested it yesterday, but it should work without a change node if you set it to output an array rather than leaving it in automatic mode.
This way you can just have split, then join, and you’re done.
[{"id":"817a0c5678906327","type":"join","z":"4be5ce8c7e250d04","name":"","mode":"custom","build":"array","property":"payload","propertyType":"msg","key":"topic","joiner":"\\n","joinerType":"str","accumulate":false,"timeout":"","count":"","reduceRight":false,"reduceExp":"","reduceInit":"","reduceInitType":"","reduceFixup":"","x":610,"y":420,"wires":[["70f3fdd2a45a789b","bb21948f0e83bede"]]},{"id":"2275806dfee0cc3e","type":"split","z":"4be5ce8c7e250d04","name":"","splt":"\\n","spltType":"str","arraySplt":1,"arraySpltType":"len","stream":false,"addname":"","x":470,"y":420,"wires":[["817a0c5678906327","07cf197bceb6401f"]]},{"id":"70f3fdd2a45a789b","type":"debug","z":"4be5ce8c7e250d04","name":"debug 3","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"true","targetType":"full","statusVal":"","statusType":"auto","x":760,"y":380,"wires":[]},{"id":"bb21948f0e83bede","type":"pac-write","z":"4be5ce8c7e250d04","device":"4449010c968c5972","dataType":"string-table","tagName":"teststrings","tableStartIndex":"","value":"","valueType":"msg.payload","name":"","x":770,"y":420,"wires":[["6384931195fa9790"]]},{"id":"babd5804480e80e8","type":"function","z":"4be5ce8c7e250d04","name":"get file","func":"msg.payload =\n \"a1,a2,a3,a4\\n\" +\n \"b1,b2,b3,b4\\n\" +\n \"c1,c2,c3,c4\\n\" +\n \"d1,d2,d3,d4\\n\" +\n \"e1,e2,e3,e4\\n\" +\n \"f1,f2,f3,f4\";\nreturn msg;","outputs":1,"timeout":0,"noerr":0,"initialize":"","finalize":"","libs":[],"x":330,"y":420,"wires":[["6abdf806c53172c6","2275806dfee0cc3e"]]},{"id":"07cf197bceb6401f","type":"debug","z":"4be5ce8c7e250d04","name":"debug 2","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"true","targetType":"full","statusVal":"","statusType":"auto","x":620,"y":460,"wires":[]},{"id":"6384931195fa9790","type":"debug","z":"4be5ce8c7e250d04","name":"debug 4","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"true","targetType":"full","statusVal":"","statusType":"auto","x":940,"y":420,"wires":[]},{"id":"4c3b16af69892afe","type":"inject","z":"4be5ce8c7e250d04","name":"→","props":[],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"","x":190,"y":420,"wires":[["babd5804480e80e8"]]},{"id":"6abdf806c53172c6","type":"debug","z":"4be5ce8c7e250d04","name":"debug 1","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"true","targetType":"full","statusVal":"","statusType":"auto","x":480,"y":380,"wires":[]},{"id":"4449010c968c5972","type":"pac-device","address":"localhost","protocol":"https","msgQueueFullBehavior":"DROP_OLD"}]
The one thing to be aware of with this method is whether or not your file ENDS with a new line, if it does, you’ll end up with an extra blank string. So, for example, if your CSV has 20 lines it it, you’ll end up with an array 21 elements long, where the last element is an empty string. This shouldn’t cause an error, but I can’t be certain about that with my limited test. If your CSV does end a new line it’s an easy fix, just add a .pop() to remove that item. I’ll include that here:
[{"id":"89d5a2a969a6e6ae","type":"function","z":"4be5ce8c7e250d04","name":".pop()","func":"msg.payload.pop();\nreturn msg;","outputs":1,"timeout":0,"noerr":0,"initialize":"","finalize":"","libs":[],"x":750,"y":420,"wires":[["bb21948f0e83bede"]]},{"id":"817a0c5678906327","type":"join","z":"4be5ce8c7e250d04","name":"","mode":"custom","build":"array","property":"payload","propertyType":"msg","key":"topic","joiner":"\\n","joinerType":"str","accumulate":false,"timeout":"","count":"","reduceRight":false,"reduceExp":"","reduceInit":"","reduceInitType":"","reduceFixup":"","x":610,"y":420,"wires":[["70f3fdd2a45a789b","89d5a2a969a6e6ae"]]},{"id":"bb21948f0e83bede","type":"pac-write","z":"4be5ce8c7e250d04","device":"4449010c968c5972","dataType":"string-table","tagName":"teststrings","tableStartIndex":"","value":"","valueType":"msg.payload","name":"","x":910,"y":420,"wires":[["6384931195fa9790"]]},{"id":"2275806dfee0cc3e","type":"split","z":"4be5ce8c7e250d04","name":"","splt":"\\n","spltType":"str","arraySplt":1,"arraySpltType":"len","stream":false,"addname":"","x":470,"y":420,"wires":[["817a0c5678906327","07cf197bceb6401f"]]},{"id":"70f3fdd2a45a789b","type":"debug","z":"4be5ce8c7e250d04","name":"debug 3","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"true","targetType":"full","statusVal":"","statusType":"auto","x":760,"y":380,"wires":[]},{"id":"6384931195fa9790","type":"debug","z":"4be5ce8c7e250d04","name":"debug 4","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"true","targetType":"full","statusVal":"","statusType":"auto","x":1080,"y":420,"wires":[]},{"id":"babd5804480e80e8","type":"function","z":"4be5ce8c7e250d04","name":"get file","func":"msg.payload =\n \"a1,a2,a3,a4\\n\" +\n \"b1,b2,b3,b4\\n\" +\n \"c1,c2,c3,c4\\n\" +\n \"d1,d2,d3,d4\\n\" +\n \"e1,e2,e3,e4\\n\" +\n \"f1,f2,f3,f4\\n\";\nreturn msg;","outputs":1,"timeout":0,"noerr":0,"initialize":"","finalize":"","libs":[],"x":330,"y":420,"wires":[["6abdf806c53172c6","2275806dfee0cc3e"]]},{"id":"07cf197bceb6401f","type":"debug","z":"4be5ce8c7e250d04","name":"debug 2","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"true","targetType":"full","statusVal":"","statusType":"auto","x":620,"y":460,"wires":[]},{"id":"4c3b16af69892afe","type":"inject","z":"4be5ce8c7e250d04","name":"→","props":[],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"","x":190,"y":420,"wires":[["babd5804480e80e8"]]},{"id":"6abdf806c53172c6","type":"debug","z":"4be5ce8c7e250d04","name":"debug 1","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"true","targetType":"full","statusVal":"","statusType":"auto","x":480,"y":380,"wires":[]},{"id":"4449010c968c5972","type":"pac-device","address":"localhost","protocol":"https","msgQueueFullBehavior":"DROP_OLD"}]
Power out here, so I have to shut down, but Eureka!!! Yes it works, thanks so much, now I’ll try the Pop next and see if I can figure out how to remove the /n at end of each line as delivered to the string table.
Ok, I am slooooowly getting it…
Here is the function block pop() with entirely new script,
/ Access the payload
let array = msg.payload;
// Ensure it’s an array
if (Array.isArray(array)) {
// Transform array: Remove first char if it’s hex 0A
msg.payload = array.map(str => {
if (str.charCodeAt(0) === 0x0A) {
return str.slice(1); // Remove the first character
}
// Remove the last character if it’s 0D
if (str.charCodeAt(str.length - 1) === 0x0D) {
str = str.slice(0, -1); // Remove the last character
}
return str;
});
} else {
// Log a warning if it’s not an array
node.warn("msg.payload is not an array. Type: " + typeof array);
}
// Return the updated message
return msg;
The problem is not so much as the ending cr, but more the fact that UTF8 ends each line with CR LF (0D 0A). I set the split to use \r but the CR still remains, even though I think it is supposed to remove CR and LF since LF comes after. So this function, removes either or both.
Works perfect, leaves the last comma, removes all 0D 0A.
Btw, the rec sting table command now works correctly, if you use CR as a line delimit, the 0A is removed and not carried to next line.
Here is another issue.
The flow works great until I try to use the current entire parameters file, which is 990 string elements by up to 350 wide.
I think this is an issue with the buffer size in the R1 Gen1. I don’t have a Gen2 at the moment, so it turns out the Gen1 will only accept about 30 lines before it causes a timeout on Pac Write Node. Up to that limit, it writes pretty fast.
Terry and I have talked and tested a few things here on this one… Its not trivial.
Please hold while I get some engineering resources involved.
How many K bytes is the CSV on the windows PC?
The whole file is something like 210k. The 30 lines I mentioned is probably around 72k assuming 300 chars wide x 30.
Yah, I think this is the same problem they also ran across in the Gen2. That seems to be fixed based on my testing, the entire file loads from the sdcard in somewhere just over 10 seconds.
Are you seeing this on the Gen 2? If so, use the new beta firmware Doug cooked up. That is what my customers are running now, and it is working perfect after a couple weeks of production runs.
Btw, let me know what Terry means whens he says “ticks”. I’m not too savvy when it comes to all this posting business…
Moving on to the other direction of data movement.
I don’t get why this starting read Pac block is not providing me any debug info.
Oops, never mind, I had the debug filters set…
While we could break this file into chunks of 10 lines per transaction, remind me again why we are not using the right tool for the job and moving this file via FTP?
Here are the two flows that each get triggered from R1 via Pac Display. One writes the parameters file from the PC the other write the string table to the PC both via a path setting from R1 for file location. The path setting is set in Pac Display.
WriteFileFromPC-NR.zip (1.5 KB)
WriteStrTableFromR1-NR.zip (977 Bytes)
As you can see, there are certain things I don’t get about posting…
Well, originally, the sdcard did not work correctly, so since you can’t do anything in the R1 using FTP without the sdcard, that was a dead end. Yes I know you could use the file space, but that is limited in size and is not non-volatile unless you save to flash all the time. None of this was going to work. Remember, I was using the Gen 2 as well, and even so, the Gen 1 as you discovered is as slow as molasses when receiving the file to a string table. So, go ahead and do it with FTP, you still have a fw problem.
Also, the other problem was sending the file to the PC due to firewall/antivirus issues. I did recently get the impression it is possible to set up a cert with the R1 and therefore in theory use ftp to send and receive the files from the R1, but I have managed to get that to work yet.
The NR approach, although not as clean as using the R1 to do it, does solve the sdcard problems and the security problems. Also, it would work every time without regard to changes in the firewall or virus programs.
Remember, the new Gen 2 FW solves the rec stable issues. It is fast, and works correctly, at least when using the sdcard, I haven’t tested this NR approach on the Gen 2, but I suspect it would work perfectly. The Gen 2 also had the rec sTable problem as well, I doubt it matters whether you are receiving from the sdcard or receiving from the NR, although I realize the command itself is not being used in the NR approach. My guess is that the Gen1 would take forever to receive a file from the sdcard as well.
Thanks for the replay.
@torchard do you think we can chunk up the file into payloads of say 10 lines until transferred?
And can we put a JavaScript ‘delay’ between each payload of about 100msec.
I think that would be the best work around to get moving on this.
I could, but I think even that approach will be relatively slow. I am going to wait until I get my Gen 2 back and try it on that first to see if the problem disappears.
I think the next thing for me to try is to get the R1 cert’d and then trying to use ftp to send and receive the files, that would be the cleanest.
I am happy to report that using the Gen 2 R1, it smokes when transferring from R1 to PC, the parameter file took maybe 1 second for 2000 lines at up to 350 chars per line. The file was about 409k.
The data file from R1 to PC also, blink of an eye for 200 lines at 800 chars per line.
The only problem is the parameter file to the R1 which was maybe a second if the file size was 204k or 1000 lines at 350 chars per line. At 2000 and at 1500 lines, it timed out. So the limit is somewhere between 1500 and 1000 lines.
So in theory, it should only take about 2 seconds to transfer a 409k file to the string table of 2k lines. I’ll look into your suggestion going forward. This is encouraging because the sdcard transfers were not this fast.
You might be confused why I changed the file size target, but it turned out the 1000 line mark was just a value I came up with from the existing customer file, which it turns out needs to accommodate up to 50 lines of new part numbers per year. Of course when I tried to increase the table size to 2000, it was out of persistent mem. I determined that the mem limit was the 1k mark, so now I have changed that table to none persistent mem, and it was all ok. So this test for the record was done with a volatile table of 2k lines instead. The customer does loose a small amount of data security, but the swap was well worth it.