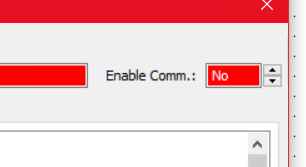
In debug, if you double click the IO unit and change the Enable Comm to Yes, does it start working?
Do you have a “Enable Communication to I/O Unit” command in the strategy? This command needs executed whenever there is a loss of connectivity to the IO unit. Opto22 has a chart you can import that handles this:
The strategy has the io enabler chart that you referenced…which I think is doing its job hence the green/yes in the enable comm in debugger.
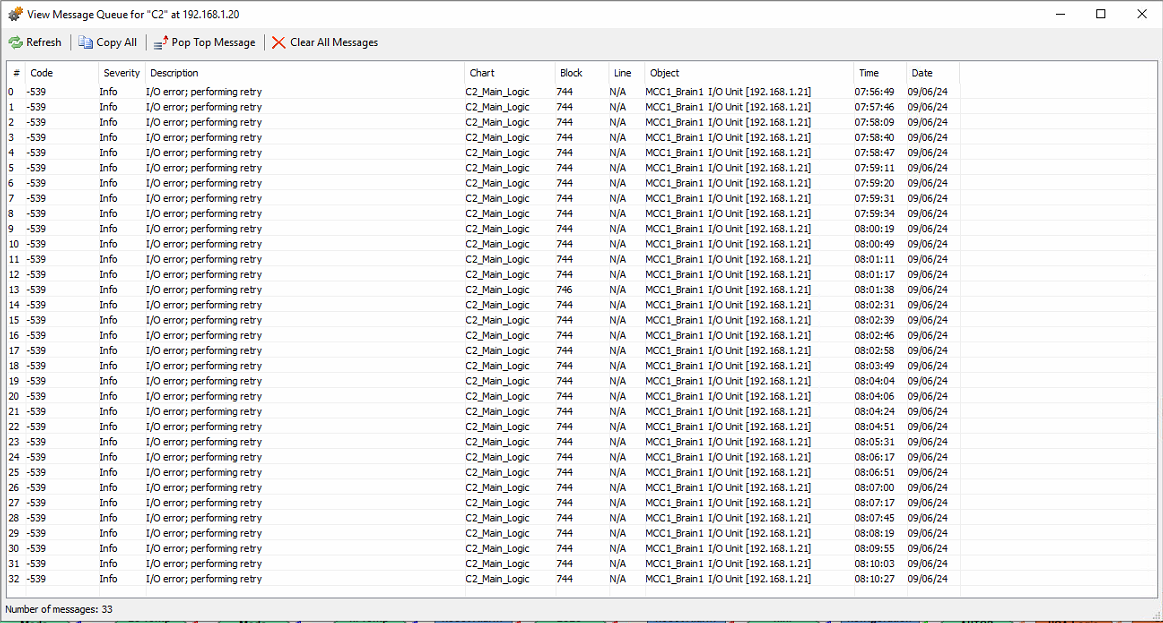
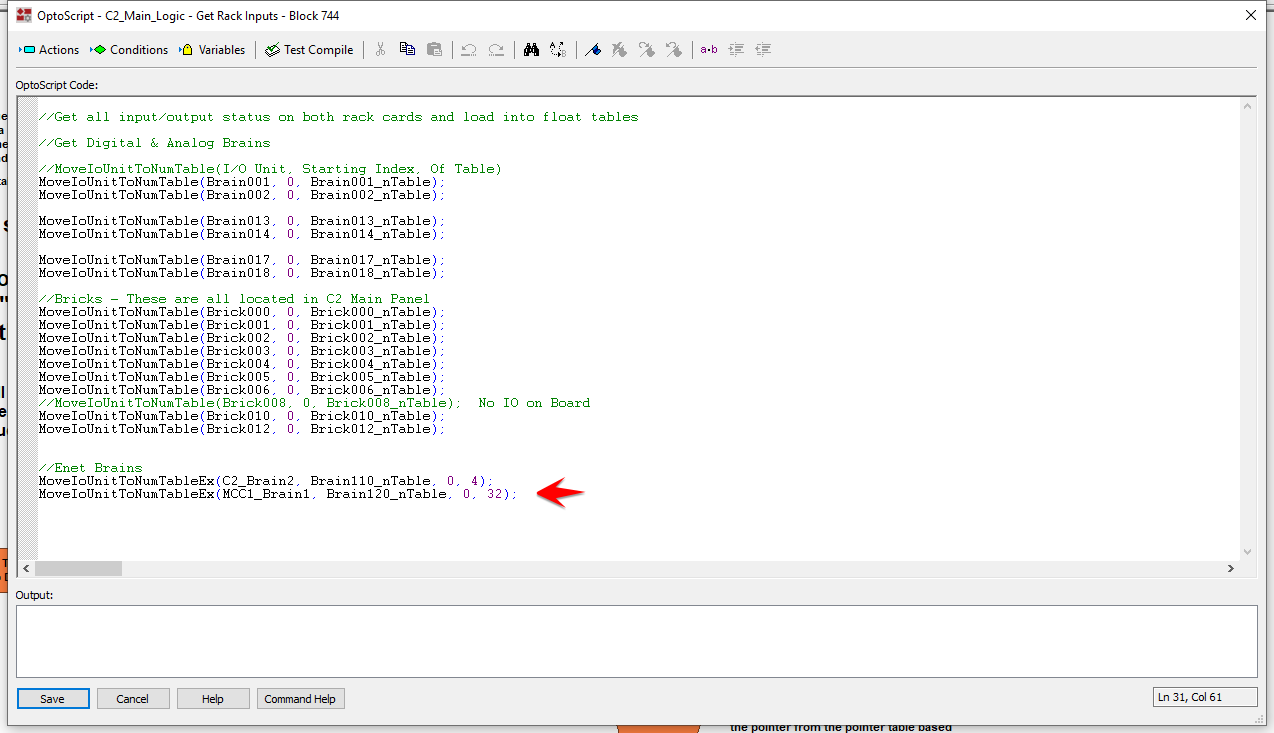
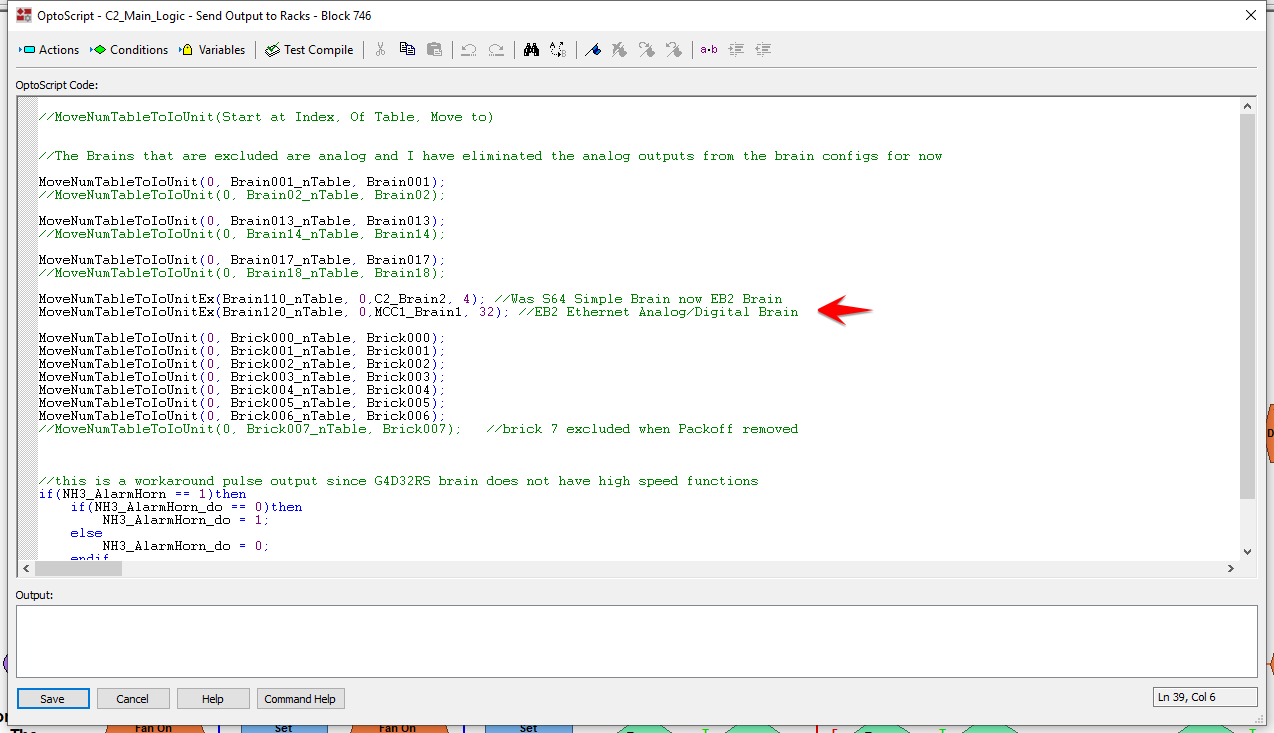
Could it be that ~10 msecs delay after the last block before the first is read again is on the threshold of requesting the “MoveIoUnitToNumTableEx(MCC1_Brain1, Brain120_nTable, 0, 32)” too often…need more delay? I will test when the customer allows for a download.
Those are blocking calls - so the frequency of reads shouldn’t cause this. Are you able to read from the IO unit through PAC Manager, inspect? Can you do it consistently? Could be a network issue - maybe duplicate IP if it is intermittent. From your log it looks to be intermittent based on the varying timestamps.
I’m hoping that you did a forum search for -539.
There are only a few results and they are all worth a read.
This one has some tips that @philip just eluded to…
The customer asked us to increase the delay from 10 msec to 100 msec. The number of errors reduced significantly. Then they asked us to go to 500 msec. We haven’t seen any errors since then.
I think @philip is right, there is probably still an ethernet communication issue we haven’t found yet.
We checked for duplicate IP addresses but did not find any.