Continuing the topic of Opto-mizing Node-Red.
Node-Red is great because its easy. The Opto22 nodes are great because its easy to get data to and from PAC or EPIC controllers.
But its also easy to get excited about that and before you know it…
Add a read node here and here and here and there and there and there……. Until… you either crashed Node-Red or rendered network connection to your controllers useless or unstable at best.
@Beno and @torchard have eluded to some best practices in this thread and the forum and I always defer to them.
These strategies or guidelines are a distillation of the Opto22 Forum knowledge base and my experiences when reading data from controllers using Node-Red.
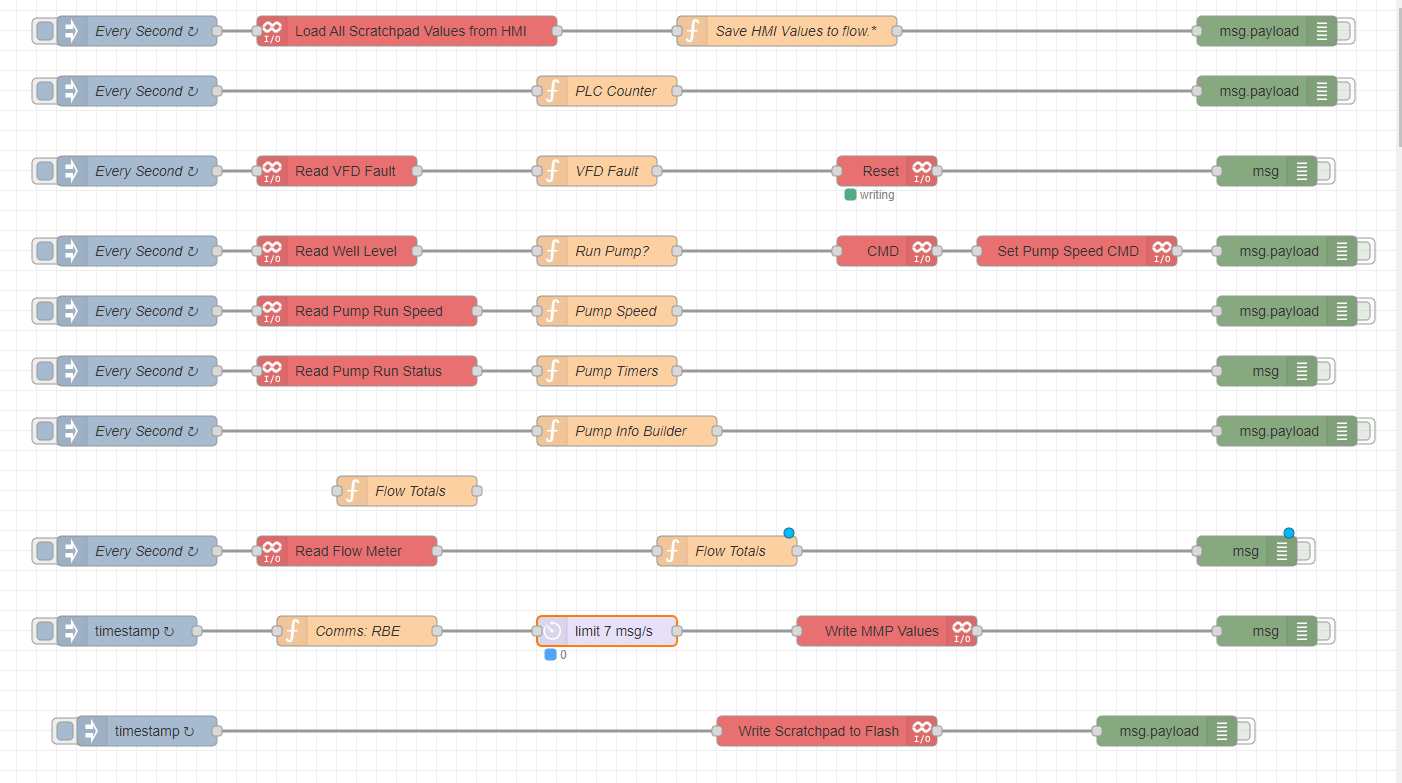
1. Centralize reading the controller(s).
Read each data type or IO from a controller once and only in one location.
This helps to organize your interactions with the controllers. (I prefer one flow tab dedicated to this)
2. Tags in bulk.
Return all tags for a each data type needed. By using global context variables and/or link nodes all tags are available to any flow in Node-Red without hitting the plc again.
*(More on global context below)
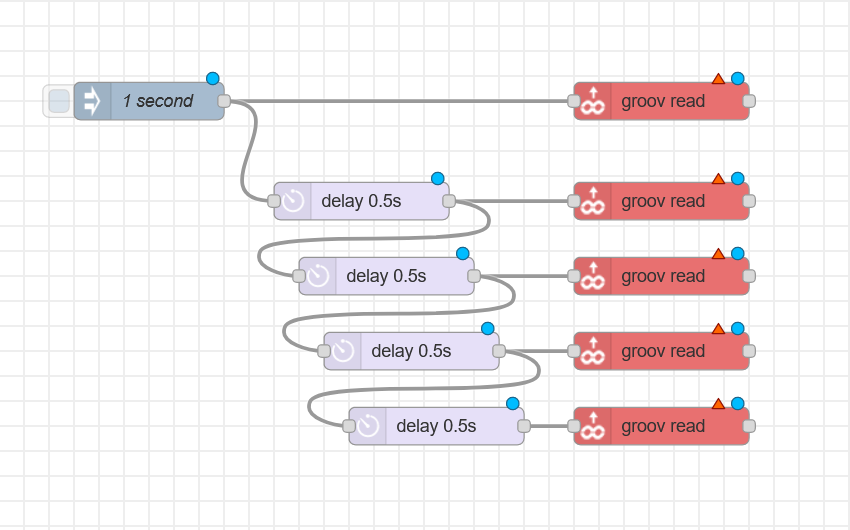
3. One request per controller at a time.
Read each data type or IO from a controller one at a time by linking nodes in series with a small delay between requests. This helps to avoid overwhelming the controller, and minimizes the chance of timeout.
4. Request interval
The interval between data updates will depend on your application. The polling rate is set at the first inject node. Ideally your timing should allow all requests to be returned before the inject node hits again to prevent overlap.
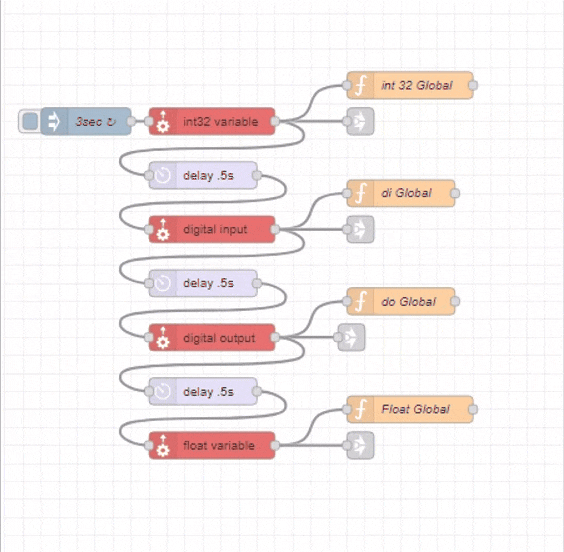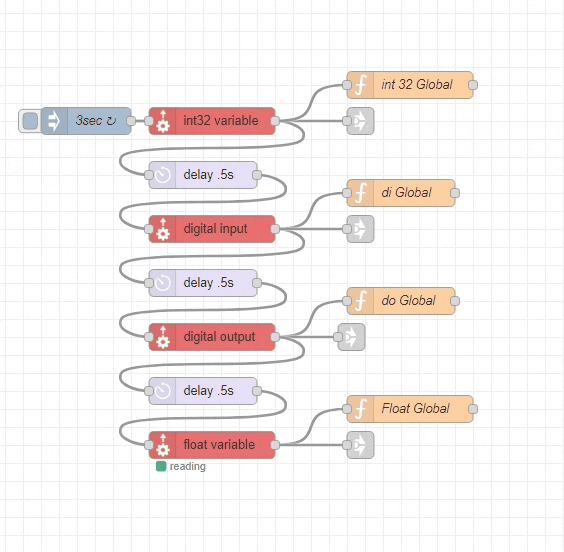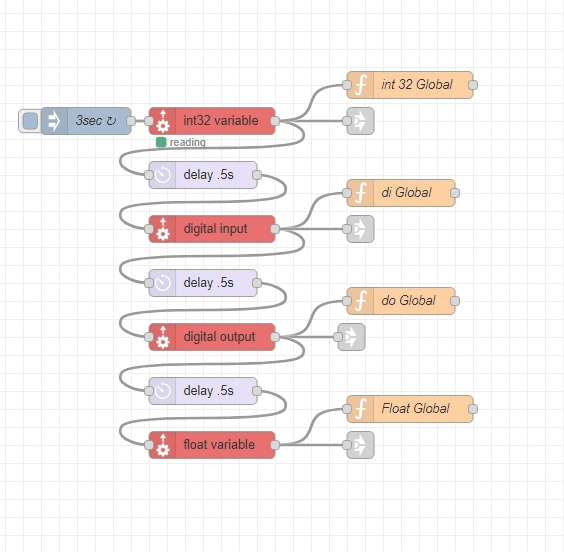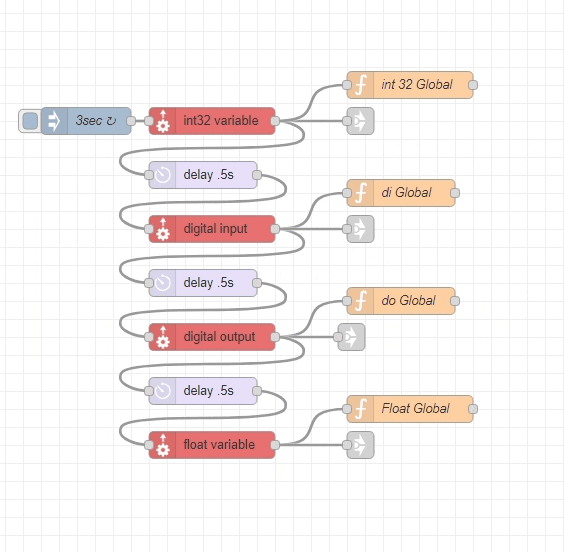
*Global Context is a powerful concept in Node-Red if you don’t use them consider it.
I use a function node to convert the array of objects:
[{"name":"f_Blanca_Hi_Alarm_Setpoint","value":18},
{"name":"f_Blanca_Lo_Alarm_Setpoint","value":15.5},
{"name":"f_Blanca_Tank_Level","value":16.5236397}]
to a single object of key value pairs (name:value).
{
"f_Blanca_Hi_Alarm_Setpoint":18,
"f_Blanca_Lo_Alarm_Setpoint":15.5,
"f_Blanca_Tank_Level":16.5236397
}
Now all tags names from the strategy can be called easily in Node-Red from the object stored in the global context .
(I also add a timestamp to each global variable object just incase I need to know how old that data is).
// Data array from controller
const array = msg.payload;
// Declare new object
var values = {};
// Timestamp
values.timestamp = new Date().getTime();
// Convert array of objects to single object of key vaule pairs
for (var i = 0; i < array.length; i++) {
values[array[i].name] = array[i].value
};
// Set to global context
global.set("int32_var", values);
return (msg);
This code chunk can be used for data arrays returned from a read node, just change the global context key string “int32_var” to whatever you want.
global.set("int32_var", values);
Hope this helps someone out there, I would love to hear feedback or about the deployment strategies you use with your organization.
-G