Is there a way to decrease the time that PAC Control is allowed to run the OpenOutgoingCommunication command before it will determine that the unit is not responding and produce a -412 error?
I have 4 pumps, each driven by a VFD and each VFD is controlled by a PAC S1 Controller using Modbus TCP. The drives work great when everything is on but if I turn off one drive, then the loop I have in my control strategy hangs up for 10 seconds every time it tries to read or write to the drive that is off and thus not responding. I definitely can’t be waiting 10 seconds for a nonresponsive drive to cause a timeout before proceeding to the next condition/command block. This could cause serious problems in the plant, like exploding pipes!
I have narrowed it down to the OpenOutgoingCommunications command which is right at the beginning of each modbus master subroutine. The issue is I don’t see how you can change the timeout to anything other than 10 seconds. Is this hard coded? Any ideas for how to prevent dangerous delays in communication with all my drives? I also can’t afford to have a chart for every drive, since eventually there will be many more of them.
The default is in fact 10 seconds for TCP comm handles. But you can change this. AFTER you open the comm handle, use the “set.to” option with the Communications Command called SendCommunicationHandleCommand.
For example, to set it to one second using OptoScript, it’d look something like:
I just spoke with Josh on the phone and he helped me with the SendCommunicationHandleCommand but that’s only going to go so far with my issue. I will eventually have many drives here (around 30) and I need to leave about 2 or 3 seconds for response on each of these or I’ll get timeouts when everything is actually ok on the network. The issue then is if the client is just doing maintenance on one part of the plant and has 10 drive off for the day, it’ll compound and make it a really long time gap between read and write commands to all the working drives.
I am probably going to have to write my strategy so that it will ignore drives with an error. I added in a “failed to open communication” variable in the modbus subroutine from the integration kit. In the “open failed” script block, I made it set a variable true, and I’ll use that as a flag. Then that will be a condition for any “open comms” commands in my strategy, so it’ll skip those commands until it is cleared by the operator.
Do you have any other ideas for how to deal with this many devices on a network using modbus? I am somewhat new to Modbus, I’ve always hard wired all my IO up to now. Surely somebody has a pretty good way to maintain responsiveness on a networked system like this where some devices may be off and some on.
Can you tell us more about the “responsiveness” you’re looking for but not seeing now? One thought – if you know there’s maintenance happening, perhaps you could add a button somewhere (if practical) to indicate “skip this one” then skip the open/etc? Also, in general, whenever you can leave a TCP comm handle open vs. open/close/open, that’s always better.
Sounds like the ideal solution would be for the modbus calls to be asynchronous - not sure how that could be done with the current integration kit other than a separate chart for each call.
Flagging the timed out VFDs sounds like a good work around. You could then have a separate chart that retries the communication for these offline VFDs until they are up again, keeping them out of your main modbus comm chart.
Mary is right about the comm handles - don’t close them (if you are), but you will still get a timeout later on in the sub.
One more thing, I would try to avoid modifying the integration kit if you can as it makes installing updates to it easier in the future. When you get a timeout, you should be able to detect that by checking the nStatus parameter of the integration kit subs. To set the timeout, you can open the comm handle yourself before you call the sub at which point you can set the timeout and then call the sub. The subs check if the handle is open, so they won’t try to open it again.
We had a similar setup/requirement with Deepsea Challenger. (Watch the video here if you are curious).
Each of the devices outside the sub were controlled and monitored via serial Modbus. The challenge was to ensure that the pilots control of the submersible was always consistent, no matter what devices might have failed (due to water ingress).
Also, depending on the dive mission, parts may or may be fitted or even turned on.
We also had some TCP (and UDP) devices in the cockpit that needed handling.
So, I think you can see it is a pretty similar situation to what you have.
How? I can’t share the exact code, and honestly, I think once you take a look at it, you will be able to make it work in your situation better than trying to leverage submarine code…
We had two methods, one was a timer per comm loop and the other was a flag per device.
As you can see it was a case of an OR statement first up, timer expired OR the device is off line? If either is true, skip it.
Then we have some other devices that just have flags. they are either connected or they are not.
If the equipment is not fitted for that dive, set the flag and just skip it all together, don’t even start its timer.
I guess the bottom line is that your post is pretty much spot on.
You can have a combination of timers or flags, or just one method… The end result is going to be a system has a very consistent poll rate regardless of how many devices are connected.
Ok, so I think I’ve got a good system set up now. Here’s what I did.
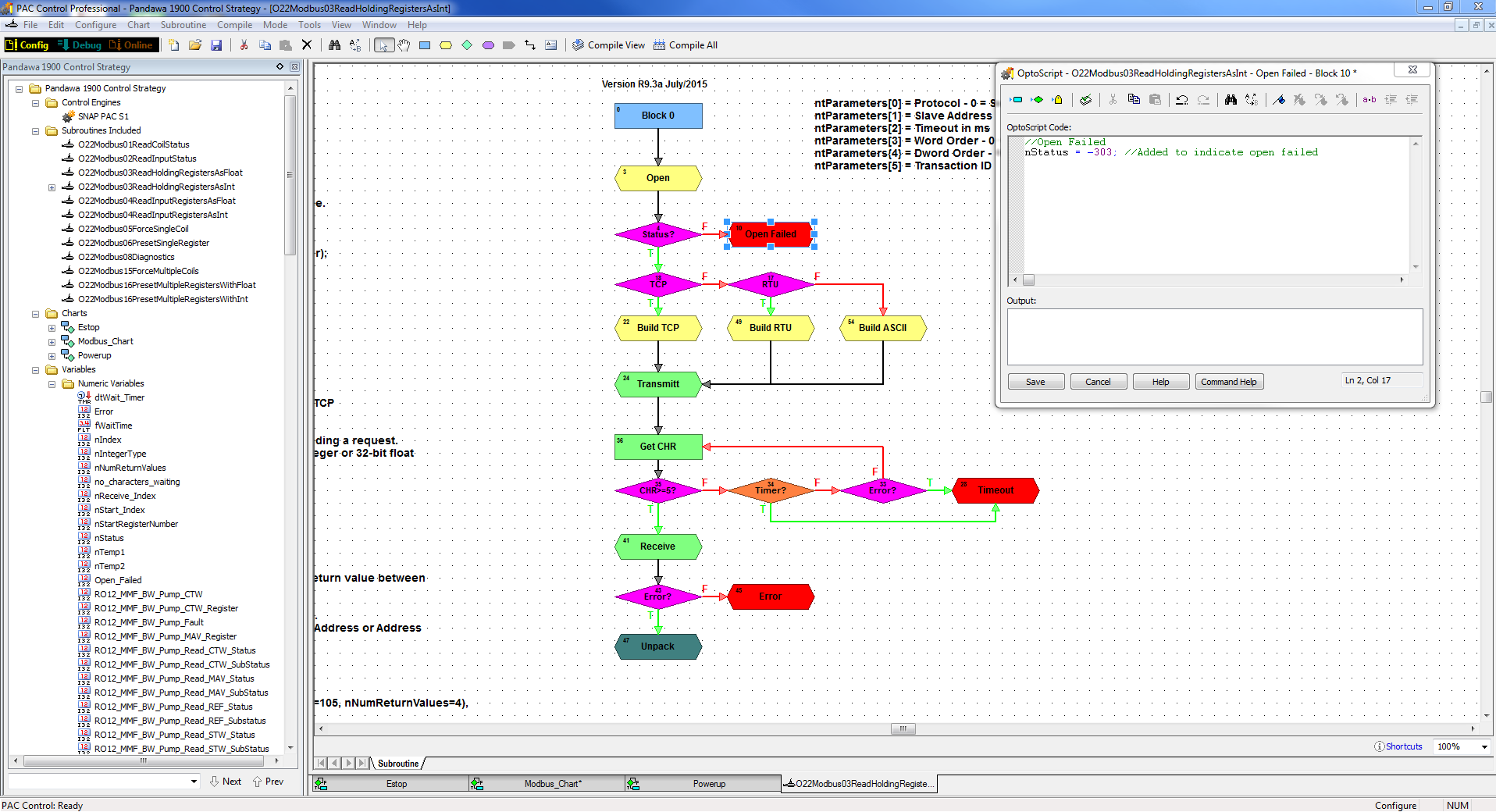
I was really only using the read multiple registers and write multiple registers commands, so there were only 3 subroutines to modify and the change is only slight. On the red “Open Failed” script block, I added “nStatus = -303;” because before, it only said //Open Failed, so you’d have no variable to tell you it ended at that block. Now I can tell when that block goes to -303, that we failed to open comms.
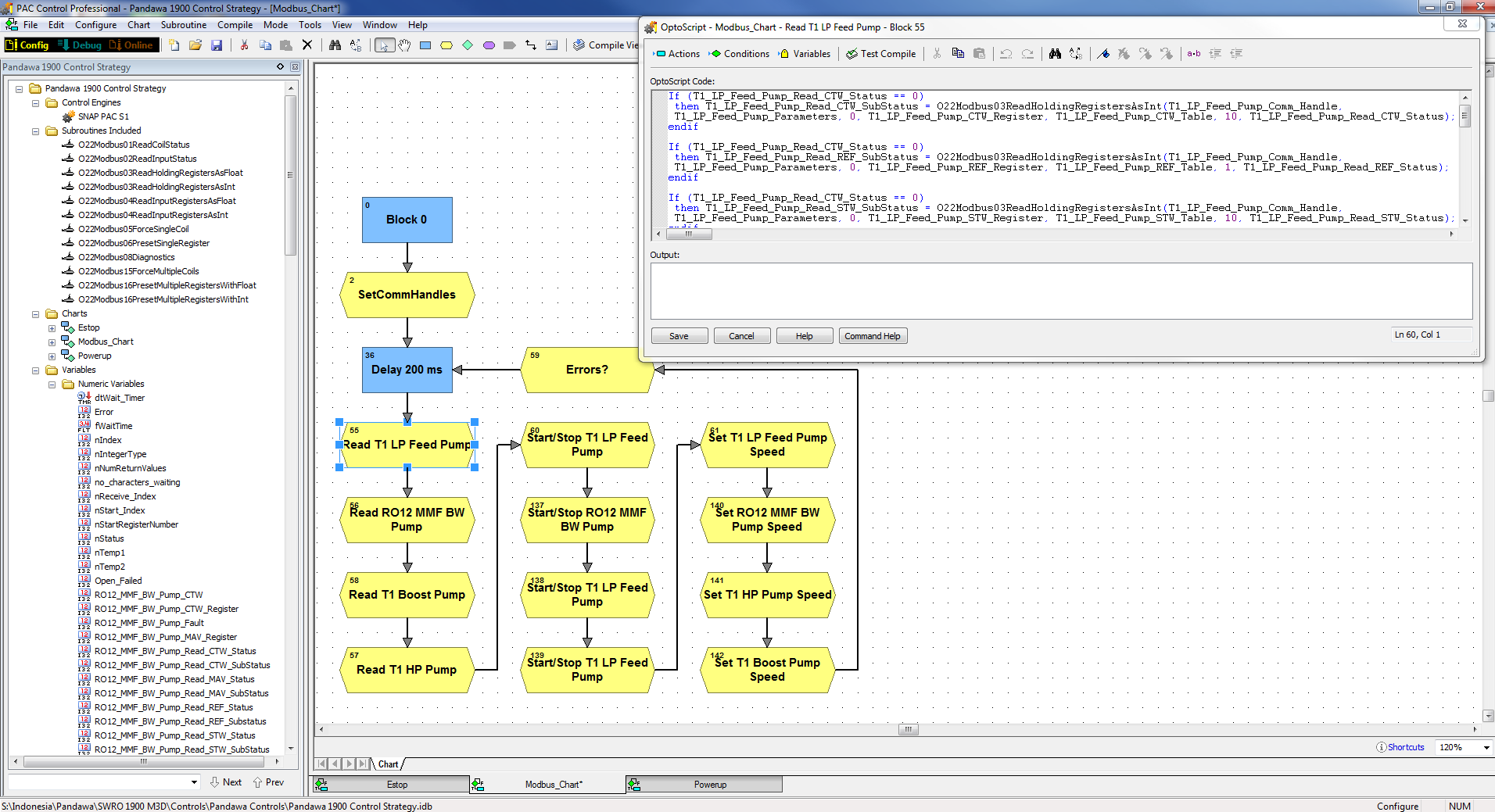
Then, on the modbus manager chart, I set up the read, and write commands in script blocks with if/then statements around each command. So for every comms command, it will only perform the command if the nStatus is 0, indicating everything is still ok. Once we get a failure, that status will be -303 or -216 and it will skip the commands. Then the operator will see the fault on the HMI in PAC Display, so they’ll have to clear all faults when they go to start that equipment back up. But that’s easy to do in one button.
I have done too many of these plants to assume that the operators will remember to click on something to set the VFD in “out of service mode” or something, so my controls have to be written for pretty hands off operation. This one is going to Bali, so if I have to troubleshoot, it can be pretty tough, and will likely be in the middle of the night for me!
Hello, can you tell me what error -216 means, I am trying to make a modbus connection with the integration kit with two drives, I tried it with node-red, but it only works when I have a single device connected, when connecting the second it does not work. nothing Works.